7. Design A Unique Id Generator In Distributed Systems
设计分布式系统中的唯一ID生成器
📝 Snowflake算法
Snowflake算法 常被称为 雪花算法,是Twitter(现“X”)开源的分布式ID生成算法,是一种分布式主键ID生成的解决方案。 雪花算法生成后是一个64bit的long型的数值,组成部分引入了时间戳,基本保持了递增。需要注意在单机上,生成的ID是递增的,但在多台机器上,只能大致保持递增趋势,并不能严格保证递增。这是因为多台机器之间的时钟不一定完全同步。
需要设计一个与分布式系统兼容的唯一ID生成器。
用传统数据库中有自增(auto_increment)属性的主键在这里行不通,因为单数据库服务器不够大,而在多个数据库服务器生成ID会有很高的延迟。
7.1 第一步: 理解问题并确定设计范围
- C:唯一ID应该具有哪些特征?
- I:它们应该是唯一的且可排序的。
- C:对于每条记录,ID是否递增1?
- I:ID按时间递增,但不一定递增1。
- C:ID是否只包含数值?
- I:是的。
- C:ID的长度要求是多少?
- I:64位。
- C:系统规模是多少?
- I:我们应该能够每秒生成10,000个ID。
7.2 第二步: 提出高层级设计并获得认可
以下是我们考虑的选项:
- 多主复制(Multi-master replication)
- 通用唯一ID(UUIDs)
- 票据服务器(Ticket server)
- Twitter的雪花算法(Twitter snowflake approach)
7.2.1 多主复制(Multi-master replication)
图7.2:
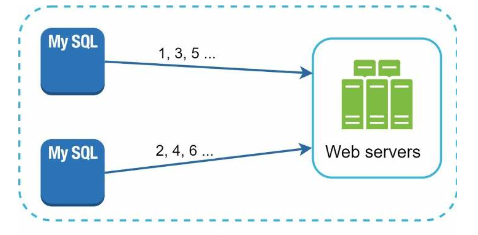
这使用数据库的自动递增功能,但不是递增1,而是递增k,其中k=服务器数量。
这解决了可扩展性问题,因为ID生成限制在单个服务器内,但它引入了其他挑战:
- 难以跨多个数据中心扩展(需要进行额外的同步和协调操作)
- ID在跨服务器时不按时间顺序递增
- 添加/删除服务器会破坏此机制,ID不能很好地随之变化
7.2.2 UUID
UUID(通用唯一标识符)是128位的唯一ID。
在全球范围内发生UUID冲突的概率非常小。
示例UUID 09c93e62-50b4-468d-bf8a-c07e1040bfb2。
优点:
- UUID可以在服务器之间独立生成,无需任何同步或协调。
- 易于扩展。每个Web服务器只负责生成它们自己使用的ID。ID生成器可以很容易地随Web服务器一起扩展。
缺点:
- ID为128位,不符合我们的要求
- ID不随时间递增
- ID可能是非数字的
7.2.3 票据服务器(Ticket server)
票据服务器是一个用于在多个服务之间生成唯一主键的中心化服务器。
图7.4:

优点:
- ID为数字
- 易于实现,适用于中小型应用程序
缺点:
- 单点故障(为了避免单点故障,可以设置多个工单服务器。但这会引入新的挑战,例如数据同步问题。)
- 由于网络调用而产生的额外延迟
7.2.4 Twitter的雪花算法(Twitter snowflake approach)
Twitter的雪花算法符合我们的设计要求,因为它按时间排序、为64位,并且可以在每台服务器中独立生成。
图7.5:

每部分的含义:
- 符号位:始终为 0。保留供将来使用。
- 时间戳: 41位。自纪元epoch(或自定义纪元epoch)以来的毫秒数。我们使用Twitter雪花算法的默认epoch
1288834974657,相当于UTC时间2010年11月4日01:42:54。 - 数据中心ID: 5位,最多支持32个数据中心。
- 机器ID: 5位,每个数据中心最多支持 32 台机器。
- 序列号: 12位,对于每个生成的ID,序列号都会递增。在每毫秒重置为0。
📝 Twitter的雪花算法
- 每台机器在每毫秒最多能生成4096个ID,即每台机器每秒最多生成245760个ID。
- 时间戳41位,1位能表示的最大时间戳是
2的41次方-1,即2,199,023,.255,551毫秒,约等于69年,只能支持69年的时间范围,但根据实际需求,可以增加时间戳的位数来延长可使用的年限,比如使用42位可以支持139年的时间范围。 - 如果我们把纪元开始时间定制得离今天的日期足够近,就可以延迟溢出时间。
7.3 第三步: 深入设计
我们将使用Twitter的雪花算法,因为它最符合我们的需求。 数据中心ID和机器ID在启动时选择。其余的在运行时确定。
📝 数据中心ID和机器ID通常在起始阶段就选好了,一旦系统运行起来,这两个部分就是固定的。对数据中心ID和机器ID所做的任何更改都需要仔细审查,因为对这些值的意外改动可能会导致ID冲突。
7.4 第四步: 总结
我们探索了多种生成唯一 ID 的方法,最终选择了雪花算法,因为它最能满足我们的目标。
其他讨论要点:
- 时钟同步: 可以使用网络时间协议(NTP)来解决不同机器/CPU核心之间的时钟不一致问题。
- ID各段长度调整: 如果并发量较低且是长时间持续运行的应用,可以牺牲一些序列号位来换取更多的时间戳位。
- 高可用性: ID生成器是一个非常关键系统,必须具有高可用性。