5. Design Consistent Hashing
设计一致性哈希系统
为了实现水平扩展,高效且均匀的在服务器之间分配请求至关重要。一致性哈希是实现此目标的常用方法。
5.1 重新哈希的问题
一种确定将请求路由到哪个服务器的方法是应用简单的哈希+取模公式:
serverIndex = hash(key) % N (其中N是服务器的数量。)这使得请求均匀地分布在所有服务器上。但是,无论何时添加或移除新服务器,上述等式的结果都会发生很大变化,这意味着大量请求将在服务器之间重新路由。
假设我们有N台缓存服务器,如果采用上面平衡负载的方法,当添加或移除缓存服务器时,就会导致大量缓存未命中,因为客户端将连接到必须重新从缓存中获取用户数据的新实例。
📝 另外还要考虑某台服务器宕机的情况
计算公式中的N是服务器总个数,还是除去宕机的机器后的数量?
- 如果是总个数,当某台服务器宕机时,某些key的客户端连接会报错误(没有冗余时)。
- 如果是除去宕机的机器后的数量,则相当于发生移除了服务器的操作,会导致大量缓存未命中。
5.2 一致性哈希
根据维基百科中的定义,“一致性哈希是一种特殊的哈希。如果一个哈希表被调整了大小,那么使用一致性哈希,则平均只需要重新映射k/n个键,这里k是键的数量,n是槽(Slot)的数量。
对比来看,在大多数传统的哈希表中,只要槽的数量有变化,几乎所有的键都需要重新映射一遍”
📝 一致性哈希是一种技术,它允许仅在N发生变化时重新映射K/N个服务器,其中K是键的数量。
例如,K=100,N=10 -> 10次重新映射,而正常情况下接近100次。
📝 一致性哈希算法
一致性哈希算法是麻省理工学院的David Karger等人首先提出的。它的基本步骤如下:
- 使用均匀分布的哈希函数将服务器和键映射到哈希环上。
- 要找出某个键被映射到了哪个服务器上,就从这个键的位置开始顺时针查找,直到找到哈希环上的第一个服务器。
5.2.1 哈希空间和哈希环(Hash space and hash ring)
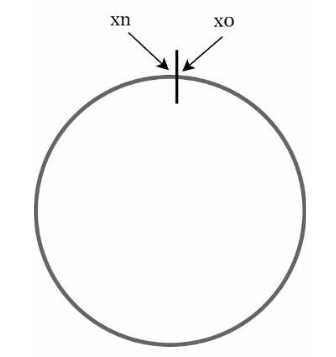
我们理解了一致性哈希的定义,让我们来了解它是如何工作的。假设使用SHA-1作为哈希函数f,哈希函数的输出范围是:x0, x1, x2, x3, ..., xn。在密码学中,SHA-1的哈希空间从0到2^160 - 1。这意味着x0对应于0,xn对应于2^160 – 1,所有中间的其他哈希值都落在0和2^160 - 1之间。图5.3展示了哈希空间。
0到2^160-1,是由其算法本身的特性决定的。图5.3:

哈希环是给定哈希算法的可能键空间的可视化,它被组合成一个类似环的结构:
图5.4:
5.2.2 哈希服务器(Hash servers)
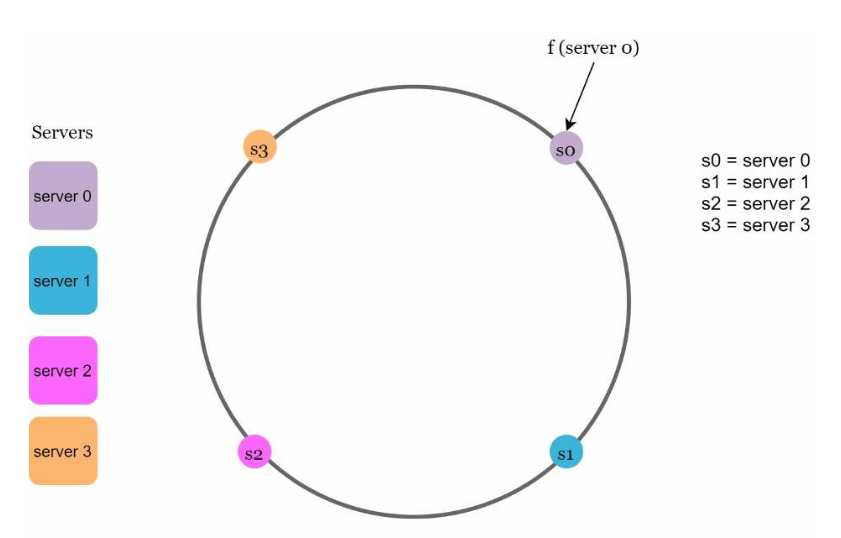
使用相同的哈希函数f处理请求,我们可以根据服务器IP或名称将服务器映射到哈希环上。
图5.5: 展示了4个服务器被映射到哈希环上的情况
5.2.3 哈希键(Hash keys)
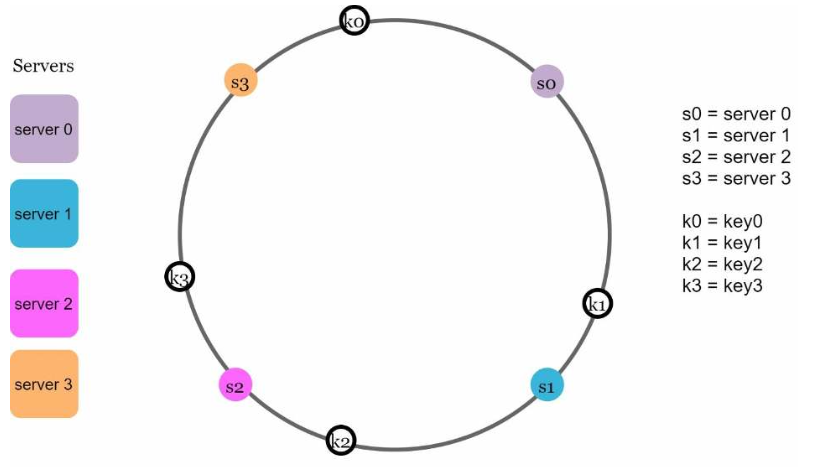
请求的哈希也沿着哈希环解析到某个位置。请注意,在这种情况下我们没有使用取模运算符:
图5.6: 4个键(key0、key1、key2和key3)被映射到哈希环上(使用的哈希函数跟5.1节中的不一样,没有求余运算)
5.2.4 查找服务器(Server lookup)
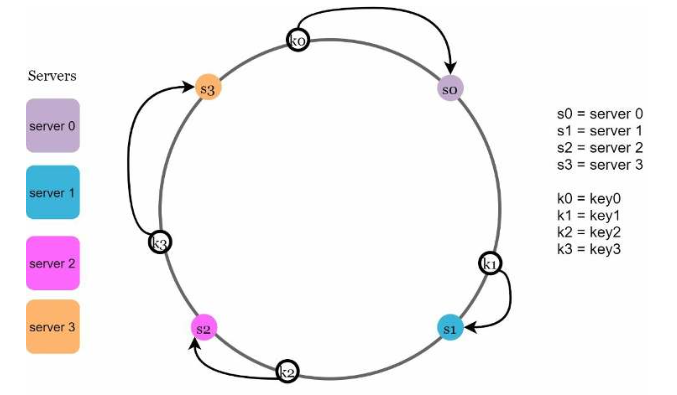
现在,要确定哪个服务器将服务于某个请求,我们从请求的哈希开始顺时针方向移动,直到到达第一个服务器哈希:
图5.7: 通过顺时针查找key0在server0上;key1在server1上;key2在server2上;key3在server3上
5.2.5 添加服务器
通过这种方法,如果要在哈希环中添加一个新的服务器,只有少部分键需要被重新映射到新的服务器上,大部分键的位置保持不变:
图5.8: 添加server4,只有key0需要重新分配位置。key1、key2和key3都保留在原来的服务器上
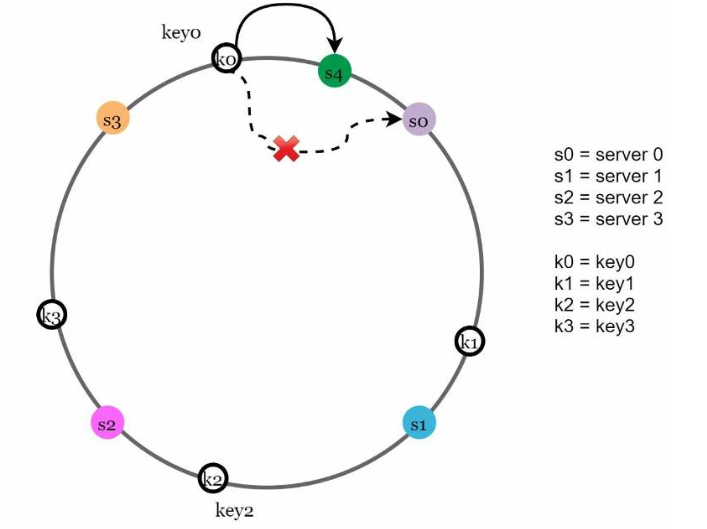
在添加server4之前,key0存储在server0上。现在,因为server4是从key0在哈希环上的位置开始顺时针查找时遇到的第一个服务器,所以key0会被存储到server4上。根据一致性哈希算法,其他的键不需要重新分配位置。
5.2.6 移除服务器
当一个服务器被移除时,如果使用一致性哈希,就只有一小部分键需要重新分配位置。
图5.9: 当移除server1时,只有key1需要重新映射到server2上,其他键则不受影响。
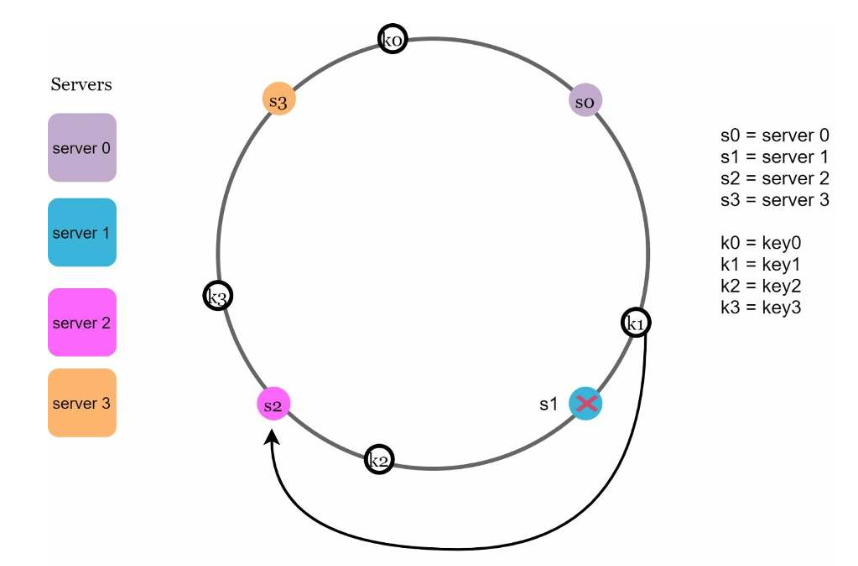
5.2.7 基本方法中的两个问题
- 因为会添加或移除服务器,所以很难保证哈希环上所有服务器的分区大小相同(分区是相邻服务器之间的哈希空间)。
- 有可能键在哈希环上是非均匀分布的。
📝 这两个问题简单总结如下:
- 哈希分区在服务器之间可能不均匀
- 请求可能在服务器之间分布不均匀(此问题源于第一个问题)
一种被称为“虚拟节点”的技术被用来解决这些问题。
5.2.8 虚拟节点
为了解决这个问题,我们可以将一个服务器多次映射到哈希环上,创建虚拟节点并将多个分区分配给同一服务器。
虚拟节点是实际节点在哈希环上的逻辑划分或映射。每个服务器都可以用多个虚拟节点来表示。
图5.12
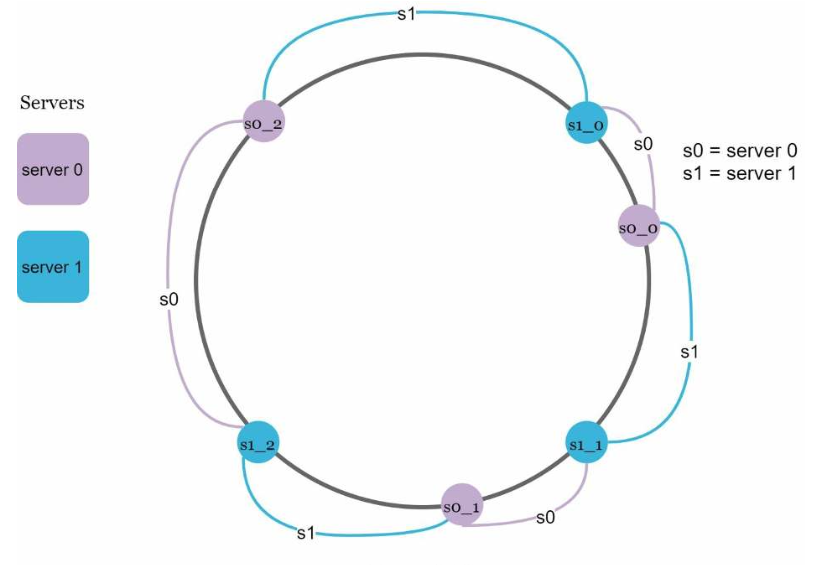
在图5.12中,server0和server1都有3个虚拟节点。这里的3是任意选择的;在实际系统中,虚拟节点的数量要大得多。
使用s0_0、s0_1和s0_2来表示环上的server0。类似地,s1_0、s1_1和s1_2表示环上的server1。有了虚拟节点,每个服务器负责多个分区。标签为s0_*的分区由server0管理。标签为s1_*的分区由server1管理。
现在,请求被映射到哈希环上最近的虚拟节点:
图5.13: 为了确定key0的服务器,从key0所在的位置出发,顺时针查找到虚拟节点s1_1,对应的是server1。
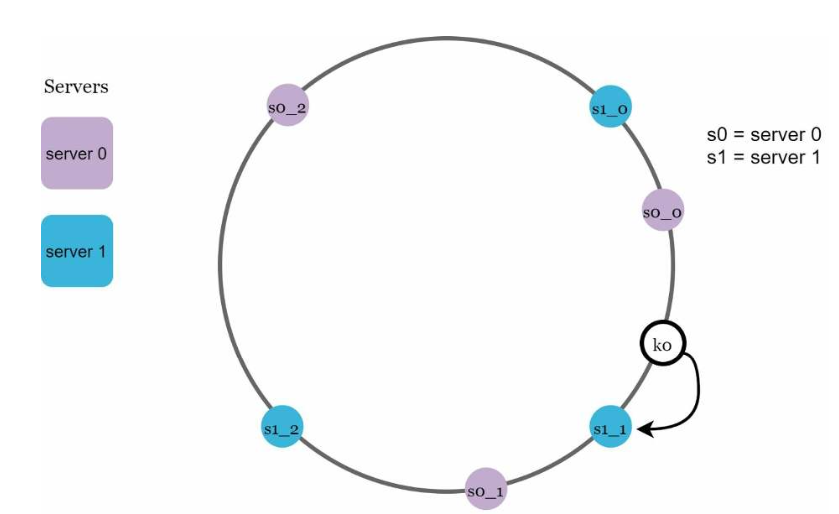
我们拥有的虚拟节点越多,键的分布就越均匀。
一项实验表明,当使用100-200个虚拟节点会导致标准差的均值为5-10%。(100个节点10%, 200个节点5%)
5.2.9 找到受影响键
当添加或移除服务器时,有一部分键需要重新分配位置。如何找到受影响的键的范围并重新为它们分配位置呢?
图5.14
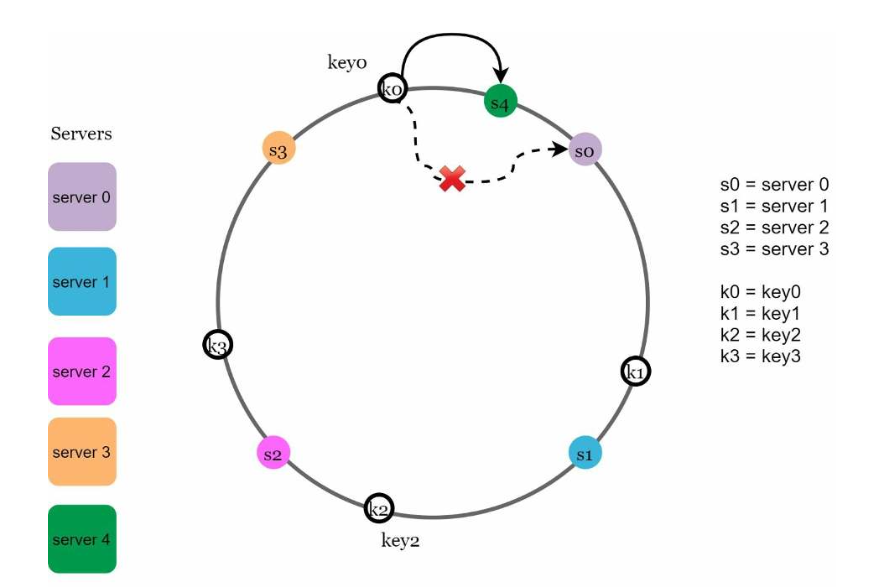
图5.14,server4被添加到哈希环上。从server4开始,沿着哈希环逆时针移动,直到遇到另一个服务器server3为止,这就是受影响的键的范围。位于server3和server4之间的键需要重新分配给server4。
图5.15
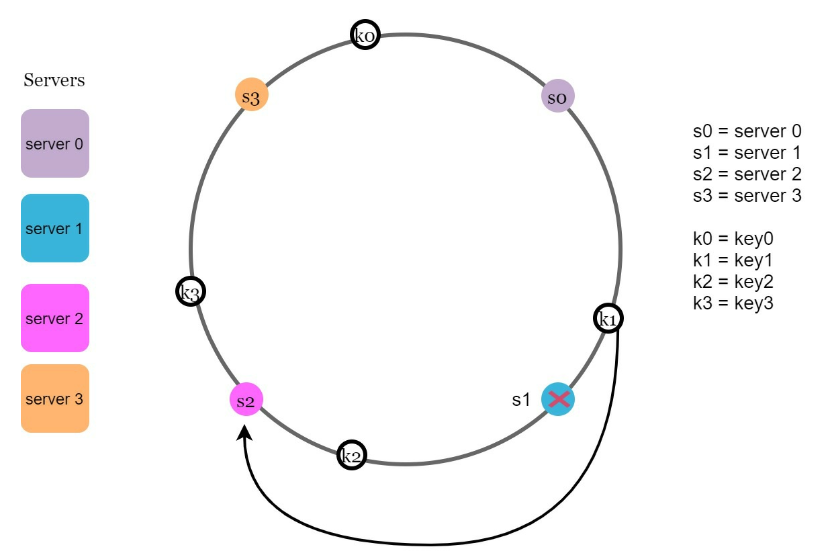
图5.15,server1被移除。从server1开始,沿着哈希环逆时针移动,直到遇到另一个服务器server0为止,这就是受影响的键的范围。位于server0和server1之间的键需要重新分配给server2。
5.3 总结
一致性哈希的优点:
- 在重新平衡时(添加或移除服务器时),只有非常少量的键被重新分配。
- 更容易横向扩展(水平扩展),因为数据分布得更均匀。
- 通过均匀分配数据来缓解热点键问题,过多访问一个特定分区可能会导致服务器过载。例如名人相关的数据是经常被访问的。
一致性哈希的实际应用示例:
- Amazon 的 DynamoDB 分区组件
- Cassandra 中的数据分区
- Discord 聊天应用程序
- Akamai CDN
- Maglev 网络负载均衡器
📝 一致性哈希、虚拟节点、扩容
一致性哈希(Consistent Hashing)是一种特殊的哈希算法。在分布式系统中,我们常常需要将数据分散存储到不同的服务器上,传统的哈希算法(例如取模运算)在服务器数量发生变化时,会导致大量数据需要重新分布,造成系统性能的剧烈波动。一致性哈希算法则可以最大限度地减少这种数据迁移的开销。
一致性哈希的核心思想:
- 构建哈希环: 将所有服务器和数据都通过哈希函数映射到一个环状的空间上。这个环通常是一个0到
2^N-1(如2^32-1)的数字环。 - 服务器映射: 将每台服务器的哈希值计算出来,并映射到哈希环上。
- 数据映射: 将每个数据的哈希值计算出来,也映射到哈希环上。
- 顺时针查找: 从数据在哈希环上的位置开始,顺时针查找最近的服务器,将数据存储到该服务器上。
一致性哈希的优点:
- 最大限度地减少数据迁移: 当增加或移除服务器时,只有部分数据需要重新分布,不会导致全局性的数据迁移。
- 负载均衡: 可以相对均匀地将数据分布到各个服务器上。
虚拟节点:然一致性哈希在一定程度上解决了数据迁移的问题,但如果服务器数量较少,或者服务器的哈希值分布不均匀,仍然可能导致数据倾斜,即某些服务器负载过高,而其他服务器负载过低。为了解决这个问题,引入了虚拟节点的概念。
虚拟节点是实际服务器在哈希环上的虚拟代表。一个实际的服务器可以映射成多个虚拟节点,这些虚拟节点均匀地分布在哈希环上。当数据映射到哈希环上时,会找到顺时针方向的最近的虚拟节点,然后将数据存储到该虚拟节点对应的实际服务器上。
虚拟节点的作用:
- 提高数据分布的均匀性: 通过增加虚拟节点的数量,可以使数据更均匀地分布到各个服务器上,减少数据倾斜的发生。
- 提高系统的稳定性: 当某个服务器宕机时,其对应的虚拟节点上的数据会被重新分布到其他服务器上,由于虚拟节点分散在哈希环上,因此可以由多个服务器共同承担故障带来的影响,提高系统的稳定性。