4. Design A Rate Limiter
设计限流器
限流器在分布式系统中的作用是控制客户端向指定服务器发送流量的速率。
限流器控制在给定时间段内允许的最大请求数。如果请求数超过阈值,则超出的请求将被限流器丢弃。
例如:
- 用户每秒最多只能发布2篇帖子
- 同一IP每天最多可以创建10个帐户
- 在同一个设备上每周最多可以领取10次奖励
几乎所有API都具有某种形式的限流器。使用限流器的好处包括:
- 防止拒绝服务(DoS)攻击
- 降低成本
- 限制过量的请求意味着需要的服务器更少,并且可以把更多的资源分配给优先级更高的API。
- 此外,有可能还会用到一些按次收费的下游服务(第三方外部API)
- 防止服务器过载。可以使用限流器来过滤机器人或者用户不当操作所造成的过量请求。
4.1 第一步: 理解问题并确定设计范围
实现限流器有多种技术,每种技术各有利弊。以下是一个候选人与面试官对话的示例:
- 候选人:我们正在设计的限流器是客户端的还是服务器端的?
- 面试官:服务器端的。
- 候选人:限流器是基于IP、用户ID还是其他什么来限制API请求的?
- 面试官:系统应该足够灵活,以支持不同的限制规则。
- 候选人:系统的规模如何?初创公司还是大型公司?
- 面试官:它应该能够处理大量的请求。
- 候选人:系统是否能在分布式环境中工作?
- 面试官:是的。
- 候选人:它应该是一个单独的服务还是一个库?
- 面试官:由你决定。
- 候选人:我们需要通知被限制的用户吗?
- 面试官:是的。
需求总结:
- 准确地限制过量的请求
- 低延迟和尽可能少的内存占用
- 分布式限流器,可以在多个服务或进程之间共享
- 异常处理,当用户的请求被拦截时,需要给用户明确的异常信息
- 高容错性: 如果限流器出现任何问题(例如某个缓存服务器宕机),不会影响整个系统
4.2 第二步: 提出高层级设计并获得认可
为简化起见,我们将采用简单的客户端-服务器模型。
4.2.1 在哪里实现限流器
限流器可以放在客户端、服务器端或者做成一个中间件。放在客户端不太靠谱,因为客户端的请求很容易被恶意伪造。此外,我们也可能无法控制客户端的具体实现。
服务端实现:
图4.1:

作为客户端与服务端的中间件:
图4.2:
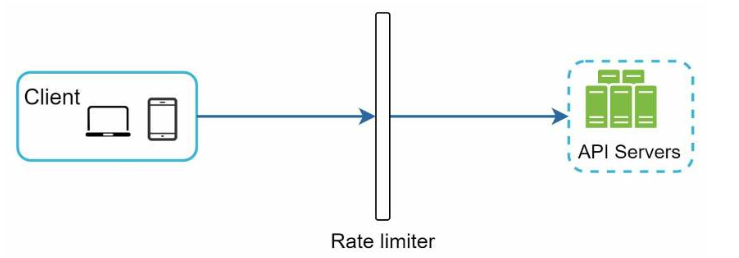
限流器工作原理如下,假设允许每秒2个请求:
图4.3:
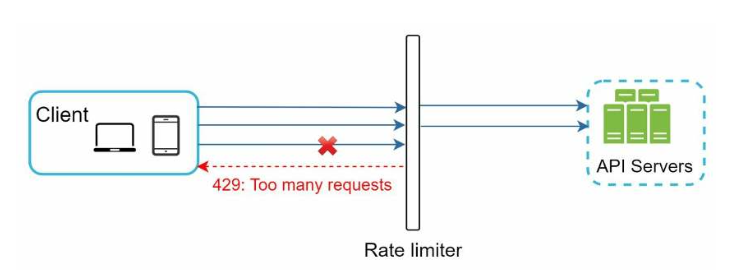
在云微服务架构中,限流一般都是在API网关中实现。该服务支持流量限制、SSL 终止、身份验证、IP 白名单、提供静态内容等功能。
那么,限流器应该在哪里实现?在服务器端还是在API网关中?
这取决于以下几个因素:
- 当前的技术栈——如果要在服务器端实现,那么所使用的编程语言应该足以支持该功能。
- 如果在服务器端实现,则可以自由的选择流量限制算法。如果使用第三方网关,则使用的算法将受到限制。
- 如果已经使用了API网关,则最好将限流器添加到其中。
- 构建自己的限流器需要时间。如果没有足够的资源,应考虑使用现成的第三方解决方案。
4.2.2 流量限制算法
存在多种算法,每种算法各有利弊。
常用的算法有:
- 令牌桶(token bucket)
- 漏桶(leaking bucket)
- 固定窗口计数器(fixed window counter)
- 滑动窗口日志(sliding window log)
- 滑动窗口计数器(sliding window counter)
令牌桶(token bucket)
该算法简单易懂,并被众多知名公司广泛采用。亚马逊和Stripe就使用该算法来对它们的API请求限流。
图4.4:
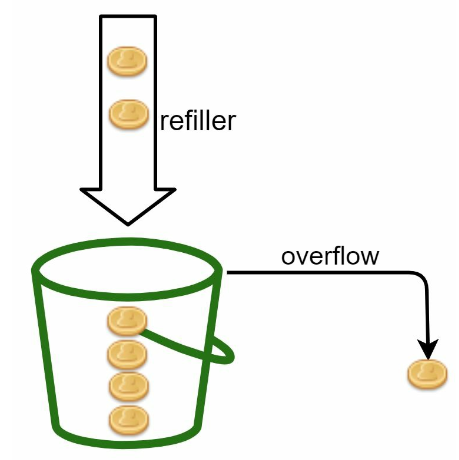
其工作原理如下:
- 存在一个具有预定义容量的容器(桶)。
- 令牌会定期放入桶中。
- 一旦桶满,将不再添加令牌。
- 每个请求消耗一个令牌。
- 如果没有剩余令牌,则请求将被丢弃。
图4.5:
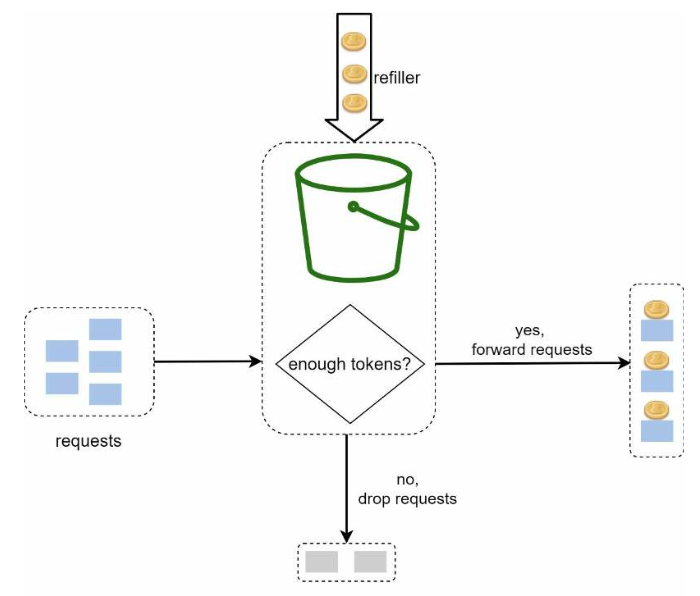
令牌桶算法有两个参数:
- 桶的大小: 桶里最多能放多少个令牌
- 补充令牌的速率: 每秒往桶里放多少个令牌
我们需要几个桶?看具体需求:
- 例如想支持每秒3条推文、每秒 5 篇帖子啥的,那可能每个API接口都要单独一个桶。
- 如果想按IP来限流,那就每个IP一个桶。
- 如果想全局限制每秒最多1万个请求,那就用一个全局的桶就行了。
优点:
- 算法容易实现
- 内存的使用效率高
- 允许在很短时间内出现突发流量。只有流量持续很高的时候才会触发限流。
缺点:
- 参数可能不太好调整。
漏桶(leaking bucket)
该算法与令牌桶算法类似,但请求以固定的速率进行处理。
其工作原理如下:
- 当请求到达时,系统检查队列是否已满。如果未满,则将请求添加到队列;否则,将其丢弃。
- 请求以固定的时间间隔从队列中取出并进行处理。
图4.7:
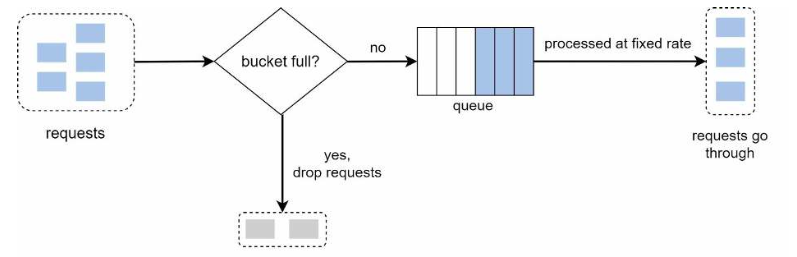
参数:
- 桶大小: 它等于队列大小。队列中保存了要按固定速率处理的请求。
- 流出速率: 它定义了每秒可以处理多少个请求,通常以秒为时间单位。
案例:Shopify是一家电商公司,它使用漏桶算法进行流量限制。
优点:
- 因为队列大小是有限的,内存的使用更高效。
- 请求以固定的时间间隔处理。适用于需要稳定流出速率的用例。
缺点:
- 突发流量会使队列大量积压旧的请求,如果这些请求不能被及时处理,最新的请求会被限流。漏桶算法可以平滑限制请求的流量,但是对于突发流量无法应对。
- 参数可能不太好调整。
固定窗口计数器(fixed window counter)
其工作原理如下:
- 时间轴被划分为固定的时间窗口,每个时间窗口都有一个计数器。
- 每个请求都会使计数器递增。
- 一旦计数器达到预先设置的阈值,该时间窗口内的后续请求将被丢弃,直到开启一个新的时间窗口
图4.8: 时间窗口大小为1秒,每个时间窗口内最多允许通过3个请求,超出的请求将被丢弃
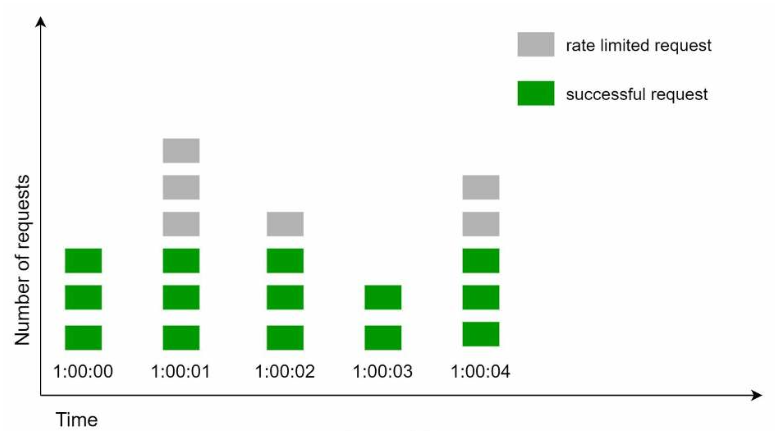
这种方法的一个主要问题是,在时间窗口边缘的突发流量可能导致通过的请求数超过允许的上限。
图4.9: 时间窗口大小为1分钟,每个时间窗口内最多允许通过5个请求,但在2:00:30和2:01:30这个1分钟之间通过了10个请求
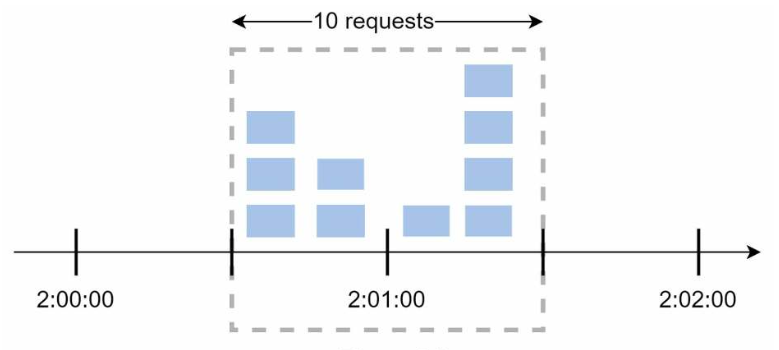
优点:
- 内存使用效率高
- 易于理解
- 在每个单位时间窗口结束时重置请求数阈值,这种设计适用于某些特定场景
缺点:
- 如果在时间窗口的边界上流量激增,导致通过的请求数超过允许的上限。
- 即如果我们设置每分钟最多10条消息,我们不希望用户能够在0:59收到10条消息,并在1:01收到另外10条消息。
滑动窗口日志(sliding window log)
其工作原理如下:
- 该算法记录请求的时间戳。时间戳数据通常保存在缓存中,例如Redis有序集合。
- 当新请求到达时,移除所有过时的时间戳。过时时间戳是指那些早于当前时间窗口起始时间的时间戳。
- 将新请求的时间戳添加到日志中。
- 如果日志大小等于或小于阈值,则允许该请求;否则,将其拒绝。
图4.10:
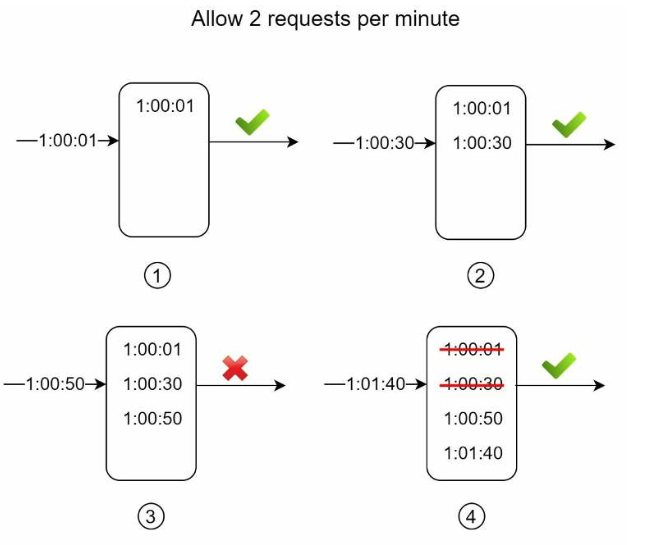
在上面的例子中,限流器每分钟允许2个请求通过。通常Linux时间戳会被存储在日志中,但是为了使可读性更高,在这里使用了人类可读的时间表示。
- 一个新请求在1:00:01到达,日志是空的,该请求被允许通过。
- 一个新请求在1:00:30到达,时间戳被写入日志。日志条数变为2,没有超过允许通过的请求数量。该请求也被允许通过。
- 一个新请求在1:00:50到达,时间戳被写入日志。日志条数变为3,大于允许通过的最大请求数。该请求被拒绝,但它的时间戳留在了日志中。
- 一个新请求在1:01:40到达,所有在
[1:00:40,1:01:40)范围内的请求都在最近的时间窗口中,所有早于1:00:40发送的请求都已过时。两个过时的时间戳1:00:01和1:00:30从日志中被删除。删除后,日志的条数变成2;因此,这个请求被允许通过。
请注意,在上面的例子中,第3个请求被拒绝,但其时间戳仍然会被记录在日志中。
优点:
- 实现的流量限制非常准确(在任何滑动的时间窗口中,请求的数量都不会超过阈值)。 缺点:
- 消耗的内存过多(因为即使一个请求已被拒绝,它的时间戳依然被保存在内存中)。
滑动窗口计数器(sliding window counter)
滑动窗口计数器算法是组合了固定窗口计数器算法和滑动窗口日志算法的方法。
其工作原理如下:
- 为每个时间窗口维护一个计数器。每个请求都会使相应时间窗口的计数器递增。
- 通过公式计算滑动窗口计数器的值:
滑动窗口请求数 = 当前窗口的请求数 + 前一个窗口的请求数 x 滑动窗口和前一个窗口的重合率。 如果计数器超过阈值,则拒绝该请求;否则,接受该请求。
图4.11:
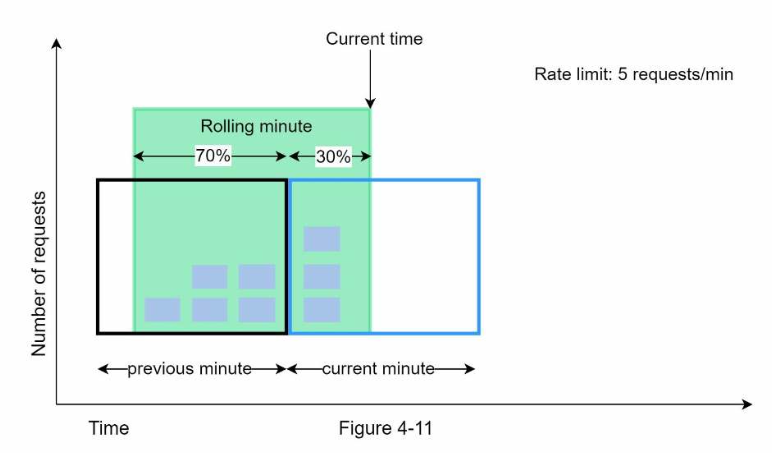
图4.11展示此算法的工作过程:
- 假设限流器每分钟最多允许通过7个请求,然后前一分钟有5个请求,当前分钟有3个请求。
- 当一个新请求出现在当前分钟的30%的位置时,滑动窗口所允许的请求数量通过下面的公式来计算:
当前窗口的请求数 + 前一个窗口的请求数 x 滑动窗口和前一个窗口的重合率- 即
3+5×0.7=6.5 - 基于不同的用户场景,对计算结果向上或者向下取整。这里向下取整为6
- 限流器每分钟允许通过7个请求,所以这个请求可以通过
优点:
- 由于当前窗口请求速率是基于前一个窗口请求的平均速率计算来的,平滑了流量中的波动,因此可以平滑流量峰值。
- 内存使用高效。
缺点:
- 由于基于重叠部分进行计算,因此流量限制不是很精确。(但根据Cloudflare的实验,在4亿个请求中,只有0.003%的请求被错误地允许通过或被限流)
4.2.3 高层级架构
前面的流量限制算法都需要"技术功能",我们将使用基于内存的缓存,Redis是一个不错的选择。
Redis的INCR适合将计数器加1,EXPIRE适合为计数器设置一个超时时间,时间到期后计数器会自动删除。
图4.12:
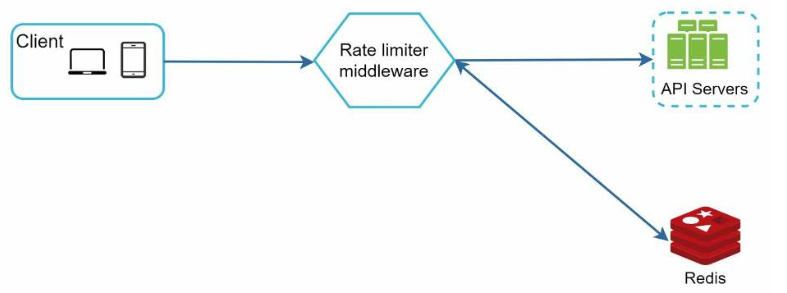
- 客户端向限流器中间件发送请求。
- 限流器中间件从Redis中获取相关计数器,根据具体限流算法执行操作,检查是否已达到限制。
- 如果已达到限制,则拒绝该请求。
- 如果未达到限制,则将该请求发送到API服务器。同时,会根据具体限流算法更新相关计数器
4.3 第三步: 深入设计
在高层级设计并没有回答下面的问题:
- 流量限制规则是如何创建的?
- 这些规则存储在哪里?
- 如何处理被限流的请求?
4.3.1 流量限制规则
Lyft针对每日5条营销消息使用的流量限制规则示例:
domain: messaging
descriptors:
- key: message_type
value: marketing
rate_limit:
unit: day
requests_per_unit: 5另一个例子,关于每分钟最大登录尝试次数:
domain: auth
descriptors:
- key: auth_type
value: login
rate_limit:
unit: minute
requests_per_unit: 5此类规则通常编写在配置文件中并保存在磁盘上。
4.3.2 超过流量的限制
如果请求被限流了,就会返回一个429(too many requests)的错误代码。
有些时候,被限流的请求可以放到队列里,等以后再处理。
我们还可以加一些额外的HTTP头部,给客户端提供更多元数据信息:
X-Ratelimit-Remaining: The remaining number of allowed requests within the window.
X-Ratelimit-Limit: It indicates how many calls the client can make per time window.
X-Ratelimit-Retry-After: The number of seconds to wait until you can make a request again without being throttled.4.3.3 详细设计
图4.13:
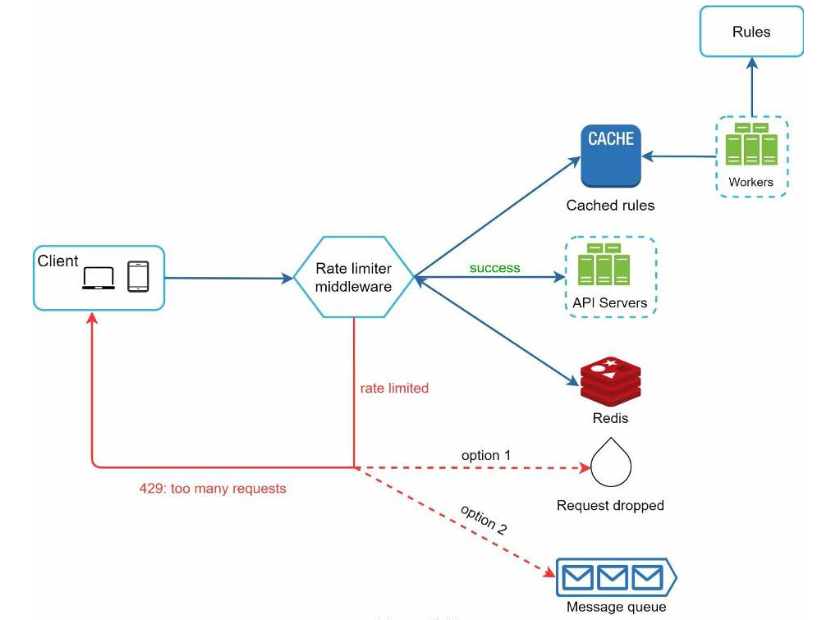
- 规则存储在磁盘上,工作进程定期将它们加载到内存缓存中。
- 限流中间件拦截客户端请求。
- 限流中间件从缓存中加载规则。它还会从Redis缓存中获取计数器。
- 如果允许请求,则将其转发到API服务器。否则,将返回429 HTTP状态代码。然后,将请求丢弃或排队。
4.3.4 分布式环境中的限流器
怎么把限流扩展到不只一台服务器?
得考虑下面几个问题:
- 竞态条件(Race condition)
- 同步(Synchronization)
在发生竞态条件的情况下,当多个实例修改计数器时,计数器可能无法正确更新:
图4.14:
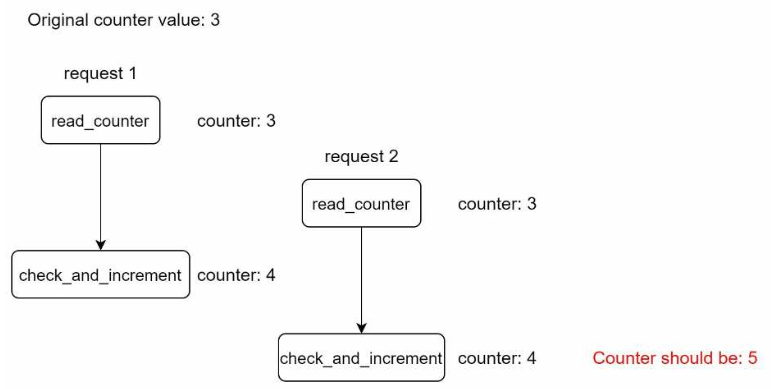
锁是解决此问题的常用方法,但其开销较大。作为替代方案,可以使用Lua脚本或Redis sorted sets,它们可以解决竞态条件。
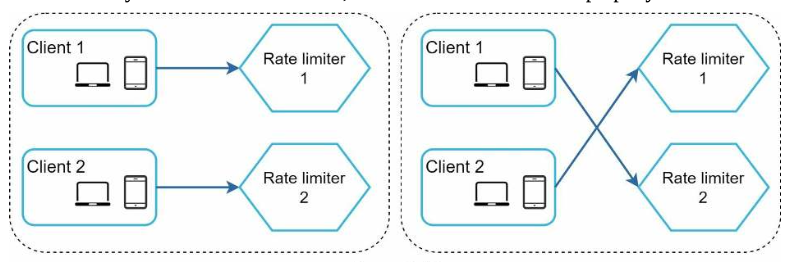
如果我们在应用程序内存中维护用户信息,则限流器是有状态的,我们需要使用粘性会话(Sticky Session)以确保来自同一用户的请求由同一限流器实例处理。
图4.15:
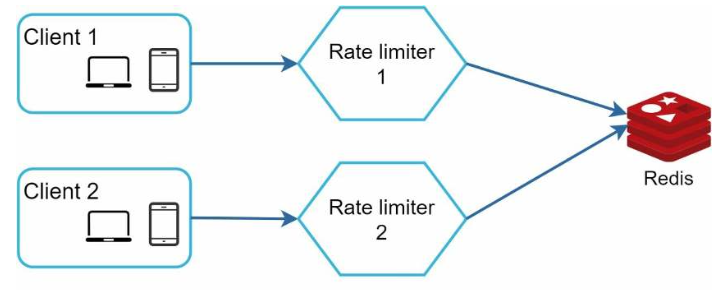
为了解决此问题,我们可以使用集中式数据存储(例如 Redis),以使限流器实例成为无状态的。
图4.16:
4.3.5 性能优化
作为针对限流器的性能优化,可以采取以下两项措施:
- 多数据中心部署,以便用户与其地理位置相近的实例进行交互。
- 使用最终一致性作为同步模型,以避免过度的锁定
4.3.6 监控
在部署限流器之后,我们需要监控其有效性。
为此,我们需监控:
- 流量限制算法是否有效
- 流量限制规则是否有效
如果丢弃的请求过多,可能需要调整一些规则或参数。
4.4 第四步: 总结
我们讨论了一系列限流算法,这些算法各有其优缺点:
- 令牌桶: 适用于支持流量突发。
- 漏桶: 适用于确保下游服务接收到一致的入站请求流量。
- 固定窗口计数器: 适用于需要将时间划分为明确窗口的特定用例。
- 滑动窗口日志: 适用于需要高精度限制但会增加内存占用的情况。
- 滑动窗口计数器: 适用于不需要100%精度且内存占用非常低的情况。
如果时间允许,可以讨论的其他要点:
- 硬性与软性流量限制
- 硬性——请求不能超过指定的阈值
- 软性——请求可以在有限的时间内超过阈值
不同层级的流量限制:
- L7(应用层)
- L3(网络层)
客户端为避免受到速率限制而采取的措施:
- 客户端缓存以避免过多的调用
- 了解限制并避免在短时间内发送过多请求
- 妥善处理因受到速率限制而产生的异常,使客户端可以优雅地从异常中恢复。
- 在重试逻辑中添加足够的退避时间