Streaming
单次LLM调用的运行时间通常远长于传统的资源请求。当您构建需要多个推理步骤的更复杂的链或代理时,这种情况会加剧。
幸运的是,LLM 是迭代生成输出的,这意味着可以在最终响应准备好之前显示合理的中间结果。因此,在输出可用时立即进行消费已成为构建 LLM 应用程序的用户体验的重要组成部分,有助于缓解延迟问题,而 LangChain 旨在对流式传输提供一流的支持。
下面,我们将讨论在 LangChain 中进行流式传输的一些概念和注意事项。
.stream() 和 .astream()
LangChain 中的大多数模块都包含 .stream() 方法(以及异步环境中的等效方法 .astream())作为方便的流式接口。.stream() 返回一个迭代器,您可以通过简单的 for 循环进行消费。以下是一个使用聊天模型的示例:
from langchain_anthropic import ChatAnthropic
model = ChatAnthropic(model="claude-3-sonnet-20240229")
for chunk in model.stream("what color is the sky?"):
print(chunk.content, end="|", flush=True)API Reference: ChatAnthropic
对于原生不支持流式传输的模型(或其他组件),该迭代器只会生成一个单独的块,但您仍然可以在调用它们时使用相同的通用模式。使用 .stream() 还会自动以流模式调用模型,而无需提供额外的配置。
每个输出块的类型取决于组件的类型——例如,聊天模型会生成AIMessageChunks。由于该方法是LangChain表达式语(LangChain Expression Language)的一部分,您可以使用输出解析器处理不同输出的格式差异,从而转换每个生成的块。
您可以查看此指南以获取有关如何使用 .stream() 的更多详细信息。
.astream_events()
虽然 .stream() 方法直观,但它只能返回链的最终生成值。这对于单次 LLM 调用来说没问题,但当您构建多个 LLM 调用组成的更复杂链时,可能希望在获取最终输出的同时使用链的中间值——例如,在构建基于文档的聊天应用时,返回最终生成结果的同时提供其来源。
可以通过使用回调,或通过构造链将中间值传递到末端(例如使用链式 .assign() 调用)来实现这一点,但 LangChain 还包括一个 .astream_events() 方法,它将回调的灵活性与 .stream() 的便利性结合在一起。调用该方法时,它会返回一个迭代器,该迭代器会生成不同类型的事件,您可以根据项目需要过滤和处理这些事件。
以下是一个简单的示例,仅打印包含流式聊天模型输出的事件:
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_anthropic import ChatAnthropic
model = ChatAnthropic(model="claude-3-sonnet-20240229")
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
parser = StrOutputParser()
chain = prompt | model | parser
async for event in chain.astream_events({"topic": "parrot"}, version="v2"):
kind = event["event"]
if kind == "on_chat_model_stream":
print(event, end="|", flush=True)API Reference: StrOutputParser | ChatPromptTemplate | ChatAnthropic
你可以大致将其理解为回调事件的迭代器(虽然格式有所不同),并且可以在几乎所有 LangChain 组件上使用它!
查看此指南以获取有关如何使用 .astream_events() 的更多详细信息,其中包括一个列出可用事件的表格。
回调
在LangChain中,从LLMs(大语言模型)流式输出的最低级别方式是通过回调系统。你可以传递一个处理 on_llm_new_token 事件的回调处理器到 LangChain 组件。当该组件被调用时,组件中包含的任何 LLM 或聊天模型都会在生成新的 token 时调用回调。在回调内,你可以将这些 token 管道传送到其他目标,例如 HTTP 响应。你还可以处理 on_llm_end 事件以执行任何必要的清理工作。
你可以查看此“操作指南”部分,了解更多关于使用回调的具体细节。
回调是 LangChain 中引入的第一个流式处理技术。尽管它功能强大且具有广泛的适用性,但对开发者来说可能不太方便。例如:
- 你需要显式初始化并管理一些聚合器(aggregator)或其他流(stream)来收集结果。
- 执行顺序没有明确保证,理论上回调可能会在
.invoke()方法结束后运行。 - 提供商通常会让你传递一个额外参数来流式传输输出,而不是一次性返回所有内容。
- 你通常会忽略实际模型调用的结果,而专注于回调的输出结果。
Token
大多数模型提供商用来衡量输入和输出的单位称为“token”。token是语言模型在处理或生成文本时读取和生成的基本单位。token的确切定义取决于模型的训练方式。例如,在英语中,一个token可以是一个单词,如“apple”,也可以是一个单词的一部分,如“app”。
当你向模型发送提示时,提示中的单词和字符会通过一个tokenizer为token。然后,模型会返回生成的输出token,tokenizer将其解码为人类可读的文本。下面的示例展示了 OpenAI 模型如何将 “LangChain is cool!” 编码为token:
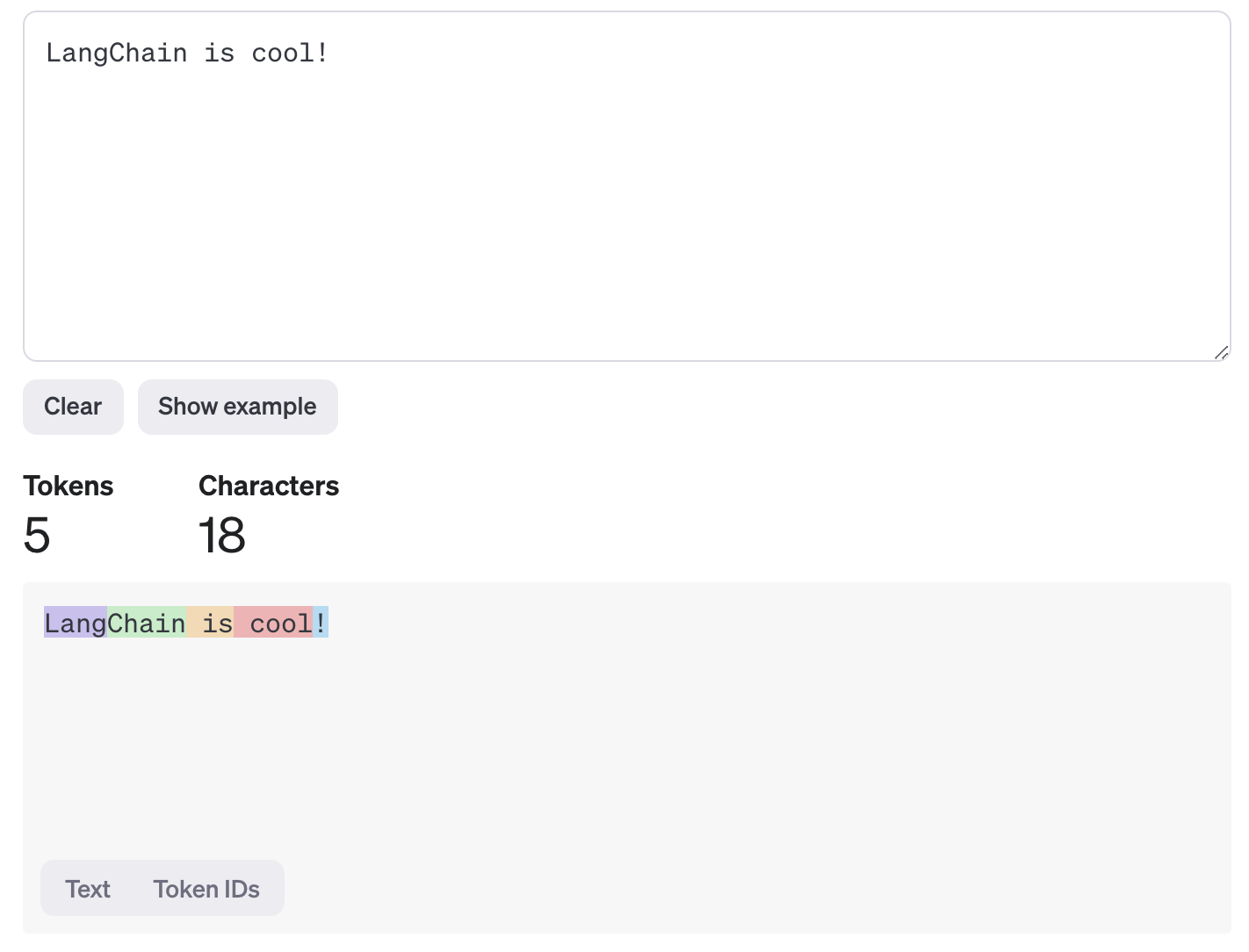
你可以看到它被分割成了5个不同的token,并且这些token的边界与单词的边界并不完全一致。
语言模型使用token而不是更直观的“字符”的原因,涉及它们处理和理解文本的方式。简单来说,语言模型是基于初始输入和之前的生成内容,迭代地预测下一个输出。使用token进行训练,让语言模型处理具有意义的语言单位(如单词或子词),而不是单个字符,这使模型更容易学习和理解语言的结构,包括语法和上下文。此外,使用token还可以提高效率,因为与按字符处理相比,模型处理的文本单位更少。