Retrieval
大型语言模型(LLM)是在一个庞大但固定的数据集上训练的,因此它们在推理私人信息或最新信息方面能力有限。通过特定事实对 LLM 进行微调是一种解决方法,但这种方法往往不适合用于事实回忆,并且成本较高。检索(Retrieval)是向 LLM 提供相关信息,以改进其对给定输入的响应。检索增强生成(RAG)是通过使用检索到的信息来支持 LLM 的生成(输出)的过程,该技术基于相关的论文。
RAG的效果取决于检索到的文档的相关性和质量。幸运的是,一系列新兴技术可以用于设计和改进RAG系统。我们专注于对许多这些技术进行分类和总结(见下图),并将在接下来的部分中分享一些高层次的策略性指导。你可以并且应该尝试将不同的技术结合使用。你可能还会觉得这份 LangSmith指南有用,它展示了如何评估应用程序的不同迭代。
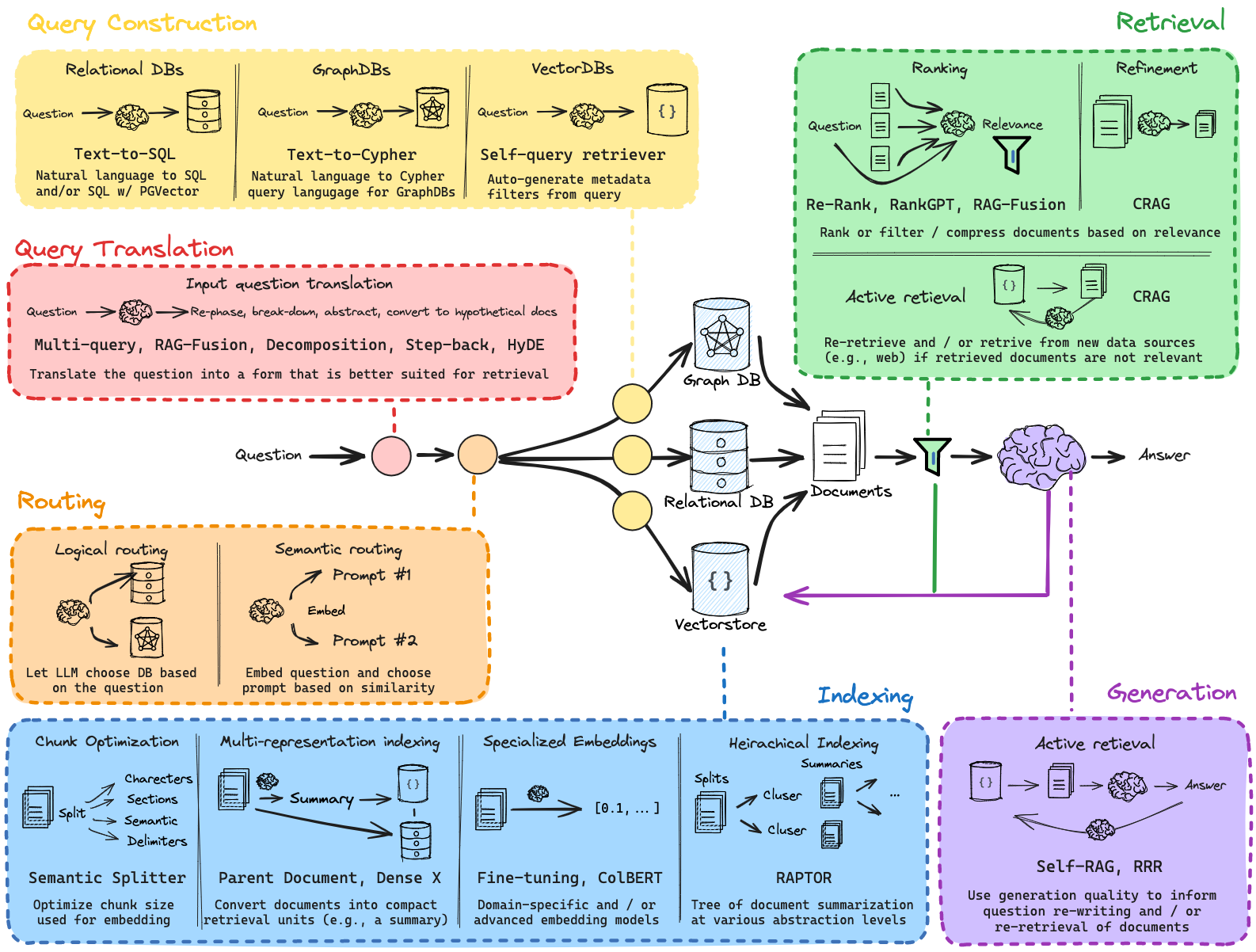
查询转换(Query Translation)
首先,考虑用户输入给你的 RAG 系统的内容。理想情况下,RAG 系统能够处理各种输入,从措辞不当的问题到复杂的多部分查询。使用 LLM 来审查并(可选地)修改输入是查询转换的核心理念。这充当了一个通用缓冲区,优化用户的原始输入以适应你的检索系统。例如,这可以简单到提取关键词,也可以复杂到为复杂查询生成多个子问题。
| 名称 | 使用场景 | 描述 |
|---|---|---|
| Multi-query | 当你需要覆盖问题的多个视角时。 | 从多个视角重写用户问题,检索每个重写问题的文档,并返回所有查询的唯一文档。 |
| Decomposition | 当一个问题可以分解为较小的子问题时。 | 将问题分解为一组子问题,可以按顺序解决(用第一个问题的答案+检索来回答第二个问题),或并行解决(将每个答案整合成最终答案)。 |
| Step-back | 当需要更高层次的概念理解时。 | 首先提示 LLM 提出一个关于更高层次概念或原则的泛化问题,并检索相关的事实。使用这些基础知识来帮助回答用户问题。 论文。 |
| HyDE | 当使用原始用户输入检索相关文档存在困难时。 | 使用 LLM 将问题转换为回答该问题的假设文档。使用嵌入的假设文档检索真实文档,前提是文档-文档的相似性搜索可以产生更相关的匹配结果。 论文。 |
路由(Routing)
其次,考虑你的 RAG 系统可用的数据源。你可能需要跨多个数据库或在结构化与非结构化数据源之间进行查询。使用 LLM 来审查输入并将其路由到合适的数据源,是在多数据源之间进行查询的一种简单且有效的方法。
| 名称 | 使用场景 | 描述 |
|---|---|---|
| 逻辑路由(Logical routing) | 当你可以通过规则提示 LLM 决定将输入路由到哪里时。 | 逻辑路由可以使用 LLM 对查询进行推理,并选择最合适的数据存储。 |
| 语义路由(Semantic routing) | 当语义相似性是确定将输入路由到何处的有效方式时。 | 语义路由将查询和一组提示嵌入,然后根据相似性选择合适的提示。 |
查询构建(Query Construction)
第三,考虑你的数据源是否需要特定的查询格式。许多结构化数据库使用SQL。向量存储通常具有用于应用关键词过滤器到文档元数据的特定语法。使用 LLM 将自然语言查询转换为查询语法是一种流行且强大的方法。特别是,text-to-SQL、text-to-Cypher 以及query analysis for metadata filters(用于元数据过滤的查询分析),分别是与结构化数据库、图数据库和向量数据库交互的有用方式。
| Name | 使用场景 | 描述 |
|---|---|---|
| Text to SQL | 如果用户提出的问题需要通过 SQL 访问关系数据库中的信息时。 | 这使用 LLM 将用户输入转换为 SQL 查询。 |
| Text-to-Cypher | 如果用户提出的问题需要通过 Cypher 访问图数据库中的信息时。 | 这使用 LLM 将用户输入转换为 Cypher 查询。 |
| Self Query | 如果用户提出的问题通过基于元数据而不是与文本的相似性获取文档能更好地回答时。 | 这使用 LLM 将用户输入转换为两部分:(1) 用于语义查找的字符串,(2) 附带的元数据过滤器。这非常有用,因为很多时候问题是关于文档的元数据(而非内容本身)。 |
索引(Indexing)
第四,考虑你文档索引的设计。一个简单而强大的想法是将用于检索的文档与传递给 LLM 进行生成的文档解耦。索引通常使用嵌入模型与向量存储,这将文档中的语义信息压缩为固定大小的向量。
许多 RAG 方法专注于将文档拆分为块,并根据与输入问题的相似性检索一定数量的块供 LLM 使用。但块的大小和数量可能难以设置,如果它们无法为 LLM 提供完整的上下文以回答问题,可能会影响结果。此外,LLM 处理数百万个token的能力日益增强。
有两种方法可以解决这一矛盾:
- Multi Vector retriever(多向量检索器)使用 LLM 将文档转换为任何适合索引的形式(例如,通常为摘要),但返回完整文档给 LLM 进行生成。
- ParentDocument嵌入文档块,但也返回完整文档。其思想是实现两全其美:使用简洁的表示(摘要或块)进行检索,但使用完整文档进行答案生成。
| 名称 | 索引类型 | 使用 LLM | 使用场景 | 描述 |
|---|---|---|---|---|
| Vector store | 向量存储 | 否 | 如果你刚开始并希望寻找一种快速简单的解决方案。 | 这是最简单的方法,也是最容易上手的方法。它涉及为每段文本创建嵌入。 |
| ParentDocument | 向量存储 + 文档存储 | 否 | 如果你的页面包含许多较小的独立信息块,这些信息块最好单独索引,但一起检索效果最好。 | 这涉及为每个文档索引多个块。然后你找到在嵌入空间中最相似的块,但检索整个父文档并返回该文档(而不是单个块)。 |
| Multi Vector | 向量存储 + 文档存储 | 有时在索引时 | 如果你能够从文档中提取信息,而认为这些信息比文本本身更相关。 | 这涉及为每个文档创建多个向量。每个向量可以通过多种方式创建,例如文本摘要和假设性问题。 |
| Time-Weighted Vector store | 向量存储 | 否 | 如果你的文档与时间戳相关联,并希望检索最新的文档。 | 这基于语义相似性(如正常的向量检索)和最近性(查看已索引文档的时间戳)组合来获取文档。 |
第五,考虑改善相似性搜索质量的方法。嵌入模型将文本压缩为固定长度(向量)表示,捕捉文档的语义内容。这种压缩对于搜索/检索非常有用,但也使得单个向量表示承载了捕捉文档语义细微差别/细节的重任。在某些情况下,无关或冗余的内容可能会稀释嵌入的语义有效性。
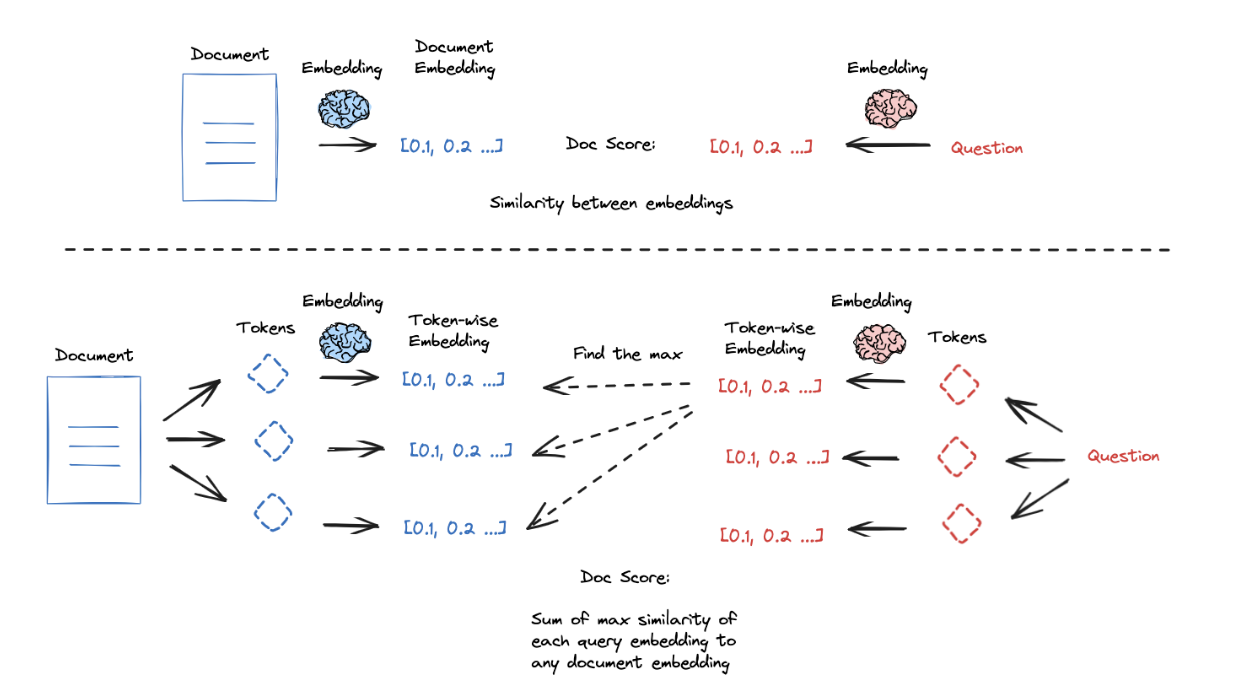
ColBERT是一种有趣的方法,通过更高粒度的嵌入来解决这个问题:
- 为文档和查询中的每个token生成上下文影响的嵌入
- 为每个查询token与所有文档token之间的相似性打分
- 取最大值
- 对所有查询token执行此操作
- 将所有查询token的最大评分(在第3步中)相加以获取查询-文档相似性评分
这种逐标记评分方法可以产生强有力的结果。
还有一些额外的技巧可以提升检索质量。嵌入在捕捉语义信息方面表现出色,但可能在基于关键词的查询中遇到困难。许多向量存储提供内置的混合检索(hybrid-search)功能,以结合关键词和语义相似性,从而融合两种方法的优点。此外,许多向量存储采用最大边界相关性(maximal marginal relevance),这种方法试图多样化搜索结果,以避免返回相似和冗余的文档。
| 名称 | 使用场景 | 描述 |
|---|---|---|
| ColBERT | 当需要更高粒度的嵌入时。 | ColBERT 使用上下文影响的嵌入为文档和查询中的每个标记生成粒度查询-文档相似性评分。 论文。 |
| Hybrid search | 当需要结合基于关键词和语义相似性时。 | 混合搜索结合了关键词和语义相似性,融合了两种方法的优点。 论文。 |
| Maximal Marginal Relevance (MMR) | 当需要多样化搜索结果时。 | MMR 试图多样化搜索结果,以避免返回相似和冗余的文档。 |
TIP
请查看我们的“从零开始学习 RAG”视频中关于ColBERT的内容
生成(Generation)
最后,考虑如何在 RAG 系统中构建自我纠正功能。RAG 系统可能会因低质量的检索(例如,如果用户问题不在索引的领域内)或生成中的幻觉而受影响。一个简单的检索-生成管道无法检测或自我纠正此类错误。在代码生成的上下文下( in the context of code generation)引入了“流工程”(“flow engineering”)的概念:通过单元测试迭代构建代码问题的答案,以检查和自我纠正错误。一些工作已经将此应用于 RAG,例如 Self-RAG 和 Corrective-RAG。在这两种情况下,都会在 RAG 答案生成流程中检查文档的相关性、幻觉和/或答案质量。
我们发现,图表是可靠表达逻辑流程的好方法,并使用 LangGraph 实现了这些论文中的一些想法,如下图所示(红色 - 路由routing,蓝色 - 回退,绿色fallback - 自我纠正self-correction):
- 路由(routing):Adaptive RAG(论文)。将问题路由到不同的检索方法,如上所述
- 回退(fallback):Corrective RAG(论文)。如果文档与查询无关,则回退到网页搜索
- 自我纠正(self-correction):Self-RAG(论文)。修复有幻觉或未解决问题的答案
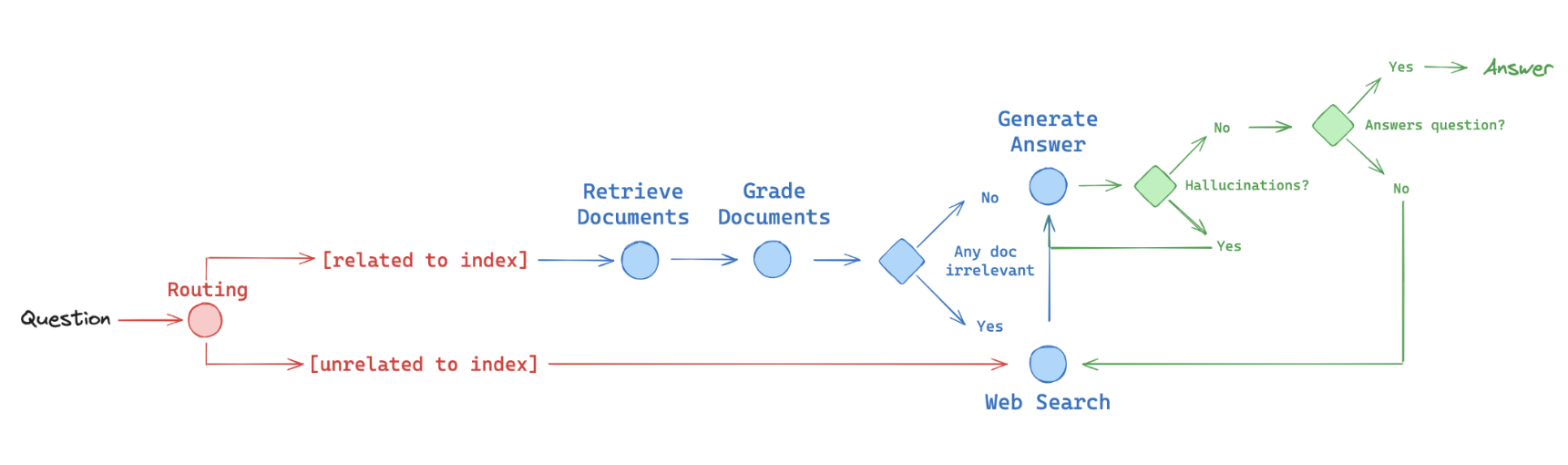
| 名称 | 适用场景 | 描述 |
|---|---|---|
| Self-RAG | 需要修复带有幻觉或不相关内容的答案时 | Self-RAG 在 RAG 答案生成流程中执行文档相关性、幻觉和答案质量的检查,迭代构建答案并自我纠正错误。 |
| Corrective-RAG | 需要低相关性文档的回退机制时 | Corrective-RAG 包含回退机制(例如回退到网页搜索),确保在检索到的文档与查询无关时提供更高质量和相关的检索。 |
TIP
请参阅多个展示如何使用 LangGraph 实现 RAG 的视频和教程:
查看我们与合作伙伴共同开发的 LangGraph RAG 案例: