CUDA
为什么要使用GPU
GPU即Graphics Processing Unit。
GPU在相同的价格和功率范围,比CPU提供更高的指令吞吐量和内存带宽。
GPU和CPU的区别在于设计目标不同。
- CPU旨在以尽可能快的速度执行一系列称为线程的操作,并且可以并行执行数十个这样的线程。
- GPU能够并行处理成千上万个线程,摊销较慢的单线程性能以实现更大的吞吐量。
GPU专门用于高度并行计算,因此设计时更多的晶体管用于数据处理,而不是数据缓存和流控制。
下图显示了CPU与GPU的芯片资源分布示例。
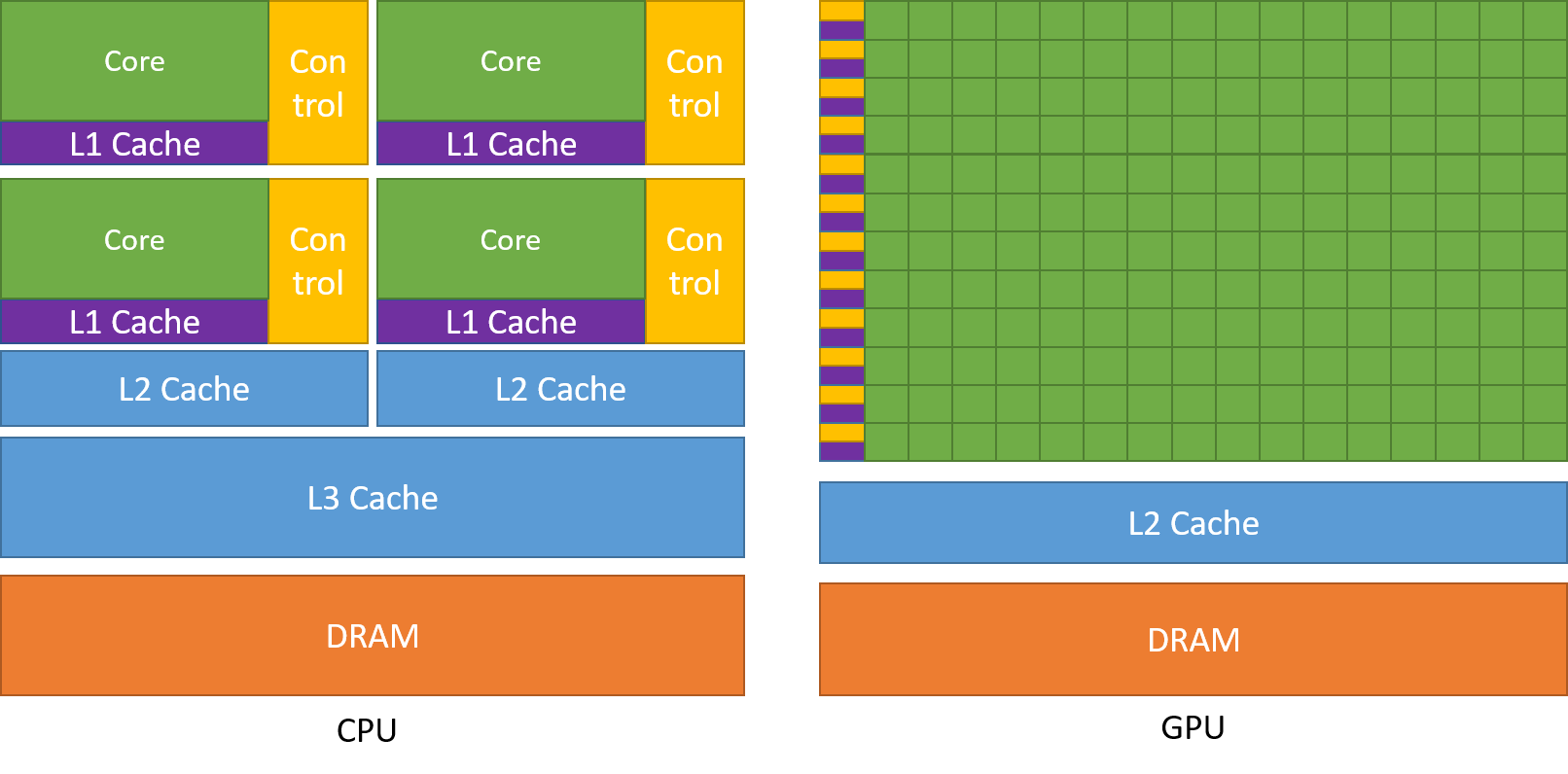
CPU通常配备较大的数据缓存(L1、L2、L3,用于存储频繁访问的数据和指令,这些缓存需要大量晶体管。 CPU复杂的流控制用于处理复杂的、不可预测的指令序列,需要先进的分支预测和乱序执行单元,这些控制单元同样需要大量晶体管
GPU将更多晶体管用于数据处理,例如浮点计算,有利于高度并行计算。
- 大量简单核心:GPU使用大量相对简单的处理单元进行并行计算。
- 吞吐量优先:GPU通过同时执行大量线程来隐藏内存访问延迟,而不是像 CPU 那样依赖大型缓存。
- 简化的控制逻辑:GPU 的控制逻辑相对简单,因为它主要处理可预测的、高度并行的任务。
通用并行计算平台和编程模型CUDA
CUDA(Compute Unified Device Architecture)是一种通用并行计算平台和编程模型,它利用NVIDIA GPU 的并行计算引擎以比CPU更有效的方式解决许多复杂的计算问题。可以使用CUDA直接访问NVIDIA GPU指令集。
CUDA附带一个软件环境,允许开发人员使用C++作为高级编程语言。
GPU在大规模矩阵乘法中的比CPU有明显的性能优势。
GPU在大规模矩阵乘法中的并行计算的性能优势。在大多数现代硬件上,应该能看到GPU比CPU快几十倍甚至上百倍。