这篇博文是基于OpenAI官方Cookbook中的以下四篇示例教程的学习笔记,主要涵盖了如何获取文本嵌入、可视化嵌入、聚类分析以及语义搜索等方面。
- Get embeddings from dataset
- Visualizing the embeddings in 2D
- K-means Clustering in Python using OpenAI
- Semantic text search using embeddings
1.创建项目
使用poetry创建一个名称为openai-embedding-sample的项目
poetry new --src openai-embedding-sample
cd openai-embedding-sample创建的项目目录结构如下:
openai-embedding-sample
├── pyproject.toml
├── README.md
├── src
│ └── openai_embedding_sample
│ └── __init__.py
└── tests
└── __init__.py配置并创建项目的虚拟环境
poetry config virtualenvs.in-project true --local
poetry env use python3.11配置使用阿里云pypi镜像,也可配置使用私有pypi源:
poetry source add --priority=primary private-pypi https://mirrors.aliyun.com/pypi/simple/添加依赖:
poetry add openai pandas matplotlib plotly scikit-learn numpy tiktoken上面的命令添加了下面的框架和库:
- openai - openai的python库
- pandas - 数据分析工具,用于处理和分析数据
- matplotlib - 用于绘制二维图表和图形
- plotly - 一个交互式可视化库,支持绘制各种类型的图表和图形
- scikit-learn - 是一个用于机器学习的库,提供了多种机器学习算法的实现
- numpy - python中用于科学计算的核心库,提供了高性能的多维数组对象和各种计算功能。
- tiktoken - 是由 OpenAI 开发的一个高效的 BPE (Byte Pair Encoding) 分词器。它主要用于将文本编码成数字序列(token),以便机器学习模型能够处理和理解文本数据
添加测试依赖:
poetry add --group=tests pytest2.理解嵌入(embedding)
2.1 嵌入(Embedding)是什么?
想象一下,我们有一堆不同种类的水果。 我们可以用文字来描述这些水果,比如“苹果”、“香蕉”、“橙子”等等。但是,如果我们想让计算机来理解这些水果之间的关系,仅仅用文字是不够的。
嵌入就是一种将这些文字转化为计算机能够理解的数字表示的方法。 这些数字表示的向量(vector)就叫做嵌入。通过这种方式,我们就可以把原本抽象的文字概念转化为具体的数值,让计算机能够更方便地进行计算和比较。
嵌入的意义:
- 降维: 嵌入将高维的文本数据映射到低维的向量空间中,这有助于减少计算量,提高模型的效率。
- 相似性计算: 嵌入能够捕捉单词或短语之间的语义和语法关系。例如,“苹果"和"香蕉"的嵌入向量会比较接近,因为它们都是水果。
- 可视化: 通过将嵌入向量可视化,我们可以直观地观察到单词之间的关系。
嵌入在自然语言处理中的应用
- 词嵌入(Word Embedding): 将单词表示为稠密向量,用于各种自然语言处理任务,如文本分类、情感分析、机器翻译等。
- 句子嵌入(Sentence Embedding): 将整个句子表示为一个向量,用于句子相似度计算、文本摘要等。
- 文档嵌入(Document Embedding): 将文档表示为一个向量,用于信息检索、推荐系统等。
嵌入的生成通常需要大量的文本数据和复杂的机器学习模型。常见的方法包括:
- Word2Vec: 通过预测上下文单词来学习词嵌入。
- GloVe: 结合了全局统计信息和局部上下文信息来学习词嵌入。
- BERT、GPT等预训练模型: 这些模型通过在大规模文本数据上进行预训练,学习到高质量的词嵌入。
Text —> Embedding Model —> Text as Vector
嵌入对于处理自然语言和代码非常有用,因为其他机器学习模型和算法(如聚类或搜索)可以轻松地使用和比较它们。
3. 亚马逊美食评论数据集
本示例使用的数据集是亚马逊的美食评论。该数据集包含了截至2012年10月亚马逊用户留下的总计568,454条美食评论。为了说明目的,我们将使用这个数据集的一个子集,包含最新的1000条评论。这些评论是英文的,倾向于正面或负面。每条评论包含产品ID(ProductId)、用户ID(UserId)、评分(Score)、评论标题(Summary)和评论正文(Text)。
我们将把评论摘要和评论正文合并成一个单一的组合文本。模型将对这个组合文本进行编码,并输出一个单个向量嵌入。
从这里下载这个数据集的1000条子集。
4. 加载数据集
import pandas as pd
import tiktoken
def main():
# 加载数据集
input_datapath = "data/fine_food_reviews_1k.csv"
df = pd.read_csv(input_datapath)
df = df[["Time", "ProductId", "UserId", "Score", "Summary", "Text"]]
df = df.dropna()df = pd.read_csv(input_datapath): 使用Pandas的read_csv函数读取CSV文件,并将数据存储到一个名为df的DataFrame中。DataFrame是Pandas中用于表示二维数据的结构。df = df[["Time", "ProductId", "UserId", "Score", "Summary", "Text"]]: 从DataFrame df中选取指定的列,包括"Time”、“ProductId”、“UserId”、“Score”、“Summary"和"Text”,并创建一个新的DataFrame。这样做的目的是只保留我们感兴趣的列。df = df.dropna(): 删除DataFrame df中包含缺失值(NaN)的行。这样可以确保后续的分析不会受到缺失值的影响。
df["combined"] = (
"Title: " + df.Summary.str.strip() + "; Content: " + df.Text.str.strip()
)
print(df.head(2))这段代码将原始数据集中的 “Summary” 和 “Text” 列合并成一个新的 “combined” 列,并在每个合并后的字符串中加入 “Title: " 和 “; Content: “,以区分摘要和正文。最后,打印出前两行数据以查看结果。
embedding_model = "text-embedding-3-small"
embedding_encoding = "cl100k_base"
max_tokens = 8000 # the maximum for text-embedding-3-small is 8191
embedding_model = "bge-large-en-v1.5"
max_tokens = 512 # the maximum for bge-large-en-v1.5 is 512embedding_model = "text-embedding-3-small"这行代码指定了要使用的嵌入模型为text-embedding-3-small。这个模型是 OpenAI 提供的一个预训练语言模型,用于生成文本嵌入。embedding_encoding = "cl100k_base"这行代码指定了用于编码文本的编码器为 cl100k_base。这个编码器是与text-embedding-3-small模型兼容的,用于将文本转换为数字序列(token)。max_tokens = 8000设置最大 token 数: 这行代码定义了文本的最大 token 数为 8000。这个限制是基于text-embedding-3-small模型的限制,超过这个限制将导致错误。
# subsample to 1k most recent reviews and remove samples that are too long
top_n = 1000
df = df.sort_values("Time").tail(
top_n * 2
) # first cut to first 2k entries, assuming less than half will be filtered out
df.drop("Time", axis=1, inplace=True)
encoding = tiktoken.get_encoding(embedding_encoding)
# omit reviews that are too long to embed
df["n_tokens"] = df.combined.apply(lambda x: len(encoding.encode(x)))
df = df[df.n_tokens <= max_tokens].tail(top_n)
print(len(df))
print(df.head(2))top_n = 1000定义一个变量top_n,用于指定最终想要保留的评论数量,这里设置为 1000。df = df.sort_values("Time").tail(top_n * 2)根据 “Time” 列对 DataFrame 进行排序,按照时间降序排列。取出排序后的 DataFrame 的最后 2000 行,作为初始筛选结果。这里乘以 2 是为了考虑到后续可能会过滤掉一部分评论,因此先取多一些数据。df.drop("Time", axis=1, inplace=True)删除 DataFrame 中的 “Time” 列,因为在后续处理中不再需要。参数inplace=True表示直接修改原 DataFrame,而不是创建一个新的副本。encoding = tiktoken.get_encoding(embedding_encoding)获取指定编码器的编码对象,这里使用的是cl100k_base编码器。df["n_tokens"] = df.combined.apply(lambda x: len(encoding.encode(x)))创建一个新的列 “n_tokens”,用于存储每条评论的 token 数量。使用apply函数对 “combined” 列中的每条文本进行处理,计算其对应的 token 数量。encoding.encode(x)将文本转换为 token 序列,len()函数计算序列的长度。df = df[df.n_tokens <= max_tokens].tail(top_n)筛选出 token 数量小于等于max_tokens的评论,并取最后 1000 条作为最终结果。print(len(df))打印最终筛选后的 DataFrame 的行数,以验证是否得到了期望的 1000 条评论。
5. 生成嵌入并保存
先写一个测试,演示一下OPENAI API的embeddings API的调用方法:
注意, 这里对代码的测试使用的本地部署的嵌入模型
bge-large-en-v1.5:
from openai import OpenAI
import os
def test_openai_api_embeddings():
OPENAI_API_BASE = os.environ.get("OPENAI_API_BASE")
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
embedding_model = "bge-large-en-v1.5"
client = OpenAI(base_url=OPENAI_API_BASE, api_key=OPENAI_API_KEY)
res = client.embeddings.create(input="abc", model=embedding_model)
print(res.data[0].embedding)运行上面的测试,会看到输出的向量数据:
pytest -rP tests/test_openai.py::test_openai_api_embeddings下面完成对亚马逊美食评论数据集的生成嵌入并保存,先定义一个生成嵌入的函数:
from typing import List
from openai import OpenAI
import os
OPENAI_API_BASE = os.environ.get("OPENAI_API_BASE")
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
client = OpenAI(base_url=OPENAI_API_BASE, api_key=OPENAI_API_KEY, max_retries=5)
def get_embedding(text: str, model="text-embedding-3-small", **kwargs) -> List[float]:
# replace newlines, which can negatively affect performance.
text = text.replace("\n", " ")
response = client.embeddings.create(input=[text], model=model, **kwargs)
return response.data[0].embedding调用这个函数生成嵌入:
# Ensure you have your API key set in your environment per the README: https://github.com/openai/openai-python#usage
# This may take a few minutes
df["embedding"] = df.combined.apply(
lambda x: get_embedding(x, model="bge-large-en-v1.5")
)
df.to_csv("data/fine_food_reviews_with_embeddings_1k.csv")读取保存嵌入的文件:
在Pandas 中,index_col参数用于指定DataFrame的索引列。索引列是DataFrame中用来唯一标识每一行的标签,有点类似于数据库中的主键。
当我们读取CSV文件时,通常会将其中一列作为索引,以便后续对数据进行高效的查找和操作。
# 读取生成嵌入的文件
df = pd.read_csv("data/fine_food_reviews_with_embeddings_1k.csv", index_col=0)
# 查看embeddings结果和长度
print(df["embedding"])python -m openai_embedding_sample
12 [-0.017417438328266144, -0.018280575051903725,...
13 [-0.027951912954449654, -0.018266700208187103,...
14 [0.027293438091874123, -0.02840059995651245, -...
15 [0.004309102427214384, -0.021994683891534805, ...
16 [0.017969520762562752, -0.0392923504114151, -0...
...
447 [0.007145790383219719, -0.0035732914693653584,...
436 [0.013964557088911533, -0.01780335046350956, 0...
437 [-0.032477207481861115, 0.0280800461769104, -0...
438 [-0.014685509726405144, 0.0015338457887992263,...
439 [-0.009211455471813679, -0.04697975143790245, ... # 查看embeddings结果第一行
print(df["embedding"][0])
print("length:", len(df["embedding"][0]))
print("type:", type(df["embedding"][0]))[0.0267749335616827, 0.003123185131698847, -0.024137750267982483, 0.057977546006441116, -0.053905557841062546, -0.04009933024644852, 0.015665242448449135, 0.06601973623037338, 0.03214592859148979, 0.02665616199374199, 0.019556688144803047, 0.024528663605451584, 0.025058161467313766, -0.009058943018317223, -0.04273372143507004, -0.03410712629556656, -0.0060263825580477715, -0.037118904292583466, -0.
......
0009543468477204442, -0.0009659237111918628, -0.05392676964402199, -0.011576066724956036, -0.007504361681640148, -0.0032890550792217255, -0.03377753123641014, -0.03155573084950447, 0.05228942632675171, -0.012785147875547409, -0.02052222564816475, -0.06280946731567383, -0.026425695046782494, 0.01089983806014061, 0.006608058698475361, 0.051717400550842285, -0.022326190024614334, -0.01687932014465332, -0.03479322791099548, 0.01124760415405035, 0.04013797640800476, 0.02007046528160572, -0.023960063233971596, 0.05589267984032631, -0.006869079079478979]
length: 22696
type: <class 'str'>可以看出df第一行embedding列的是一个长度是22696的字符串。
将字符串转换为向量:
# 将字符串转换为向量
df["embedding"] = df["embedding"].apply(literal_eval).to_list()
print("length:", len(df["embedding"][0]))
print("type:", type(df["embedding"][0]))length: 1024
type: <class 'list'>转换完成后,可以看到第一行数据列表的长度是1024,这和嵌入模型bge-large-en-v1.5的维度(dimensions)的1024是一致的。
打印前2行的数据:
print(df.head(2)) ProductId UserId Score Summary Text combined n_tokens embedding
12 B000K8T3OQ AK43Y4WT6FFR3 1 Broken in a million pieces Chips were broken into small pieces. Problem i... Title: Broken in a million pieces; Content: Ch... 120 [-0.017417438328266144, -0.018280575051903725,...
13 B0051C0J6M AWFA8N9IXELVH 1 Deceptive description On Oct 9 I ordered from a different vendor the... Title: Deceptive description; Content: On Oct ... 157 [-0.027951912954449654, -0.018266700208187103,...6. 将嵌入在二维空间中可视化(Visualizing the embeddings in 2D)
我们将使用t-SNE将嵌入维度从1024降至 2。一旦嵌入被降维到二维,我们就可以将它们绘制在二维散点图上。
注: Visualizing the embeddings in 2D 原文中使用的是OpenAI的嵌入模型
text-embedding-3-small,text-embedding-3-small的维度是1536>
6.1 降维
我们使用 t-SNE 降维方法将数据从1024维降到2维。
将df[“embedding”]转换为numpy数组:
# 将df["embedding"]转换为numpy数组
matrix = np.array(df["embedding"].to_list())
assert len(matrix) == 997 # 数据行数
print(type(matrix)) # <class 'numpy.ndarray'>
assert len(matrix[0]) == 1024 # 向量维度
print(type(matrix[0])) # <class 'numpy.ndarray'>创建一个 t-SNE 模型并转换数据:
from sklearn.manifold import TSNE
# Create a t-SNE model and transform the data
tsne = TSNE(
n_components=2, perplexity=15, random_state=42, init="random", learning_rate=200
)
vis_dims = tsne.fit_transform(matrix)
assert vis_dims.shape == (997, 2)6.2 绘制嵌入点(Plotting the embeddings)
我们将根据星级对每个评论着色,从红色到绿色。 即使在降维到二维空间后,我们仍然可以观察到数据点之间相当明显的区分。
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
colors = ["red", "darkorange", "gold", "turquoise", "darkgreen"]
x = [x for x, y in vis_dims]
y = [y for x, y in vis_dims]
color_indices = df.Score.values - 1
colormap = matplotlib.colors.ListedColormap(colors)
plt.scatter(x, y, c=color_indices, cmap=colormap, alpha=0.3)
for score in [0, 1, 2, 3, 4]:
avg_x = np.array(x)[df.Score - 1 == score].mean()
avg_y = np.array(y)[df.Score - 1 == score].mean()
color = colors[score]
plt.scatter(avg_x, avg_y, marker="x", color=color, s=100)
plt.title("Amazon ratings visualized in language using t-SNE")
plt.savefig("visualized-using-t-sne.png")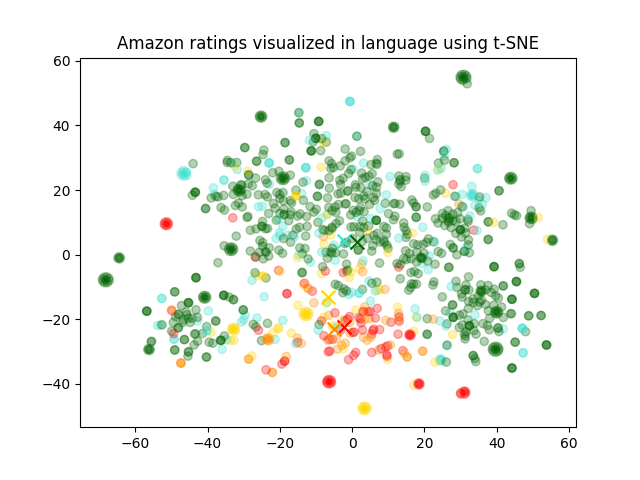
从可视化的图片可以看出,使用TSNE降维后,数据大概分成了绿、黄、红三类。
7.K-means Clustering in Python using OpenAI
K-means Clustering: K-means 聚类,一种常用的聚类算法,将数据点划分为 K 个不同的簇。
我们使用简单的 K-means 聚类算法来演示如何进行聚类。聚类可以帮助发现数据中隐藏的有价值的组群。
import numpy as np
import pandas as pd
from ast import literal_eval
def test_k_means_clustering_in_python_using_openai():
# load data
datafile_path = "./data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["embedding"] = df.embedding.apply(literal_eval).apply(np.array)
# convert string to numpy array
matrix = np.vstack(df.embedding.values)
assert matrix.shape == (997, 1024)pytest -rP tests/test_openai.py::test_k_means_clustering_in_python_using_openai7.1 使用 K-means 找到聚类
我们展示了 K-means 最简单的用法。你可以根据具体应用场景选择最合适的聚类数量。
from sklearn.cluster import KMeans
n_clusters = 4
kmeans = KMeans(n_clusters=n_clusters, init="k-means++", random_state=42)
kmeans.fit(matrix)
labels = kmeans.labels_
df["Cluster"] = labels
print(df.groupby("Cluster").Score.mean().sort_values())输出结果如下:
Cluster
3 3.706186
2 4.144444
1 4.325658
0 4.467085
Name: Score, dtype: float64 from sklearn.manifold import TSNE
import matplotlib
import matplotlib.pyplot as plt
tsne = TSNE(
n_components=2, perplexity=15, random_state=42, init="random", learning_rate=200
)
vis_dims2 = tsne.fit_transform(matrix)
x = [x for x, y in vis_dims2]
y = [y for x, y in vis_dims2]
for category, color in enumerate(["purple", "green", "red", "blue"]):
xs = np.array(x)[df.Cluster == category]
ys = np.array(y)[df.Cluster == category]
plt.scatter(xs, ys, color=color, alpha=0.3)
avg_x = xs.mean()
avg_y = ys.mean()
plt.scatter(avg_x, avg_y, marker="x", color=color, s=100)
plt.title("Clusters identified visualized in language 2d using t-SNE")
plt.savefig("clusters-visualized-using-t-sne.png")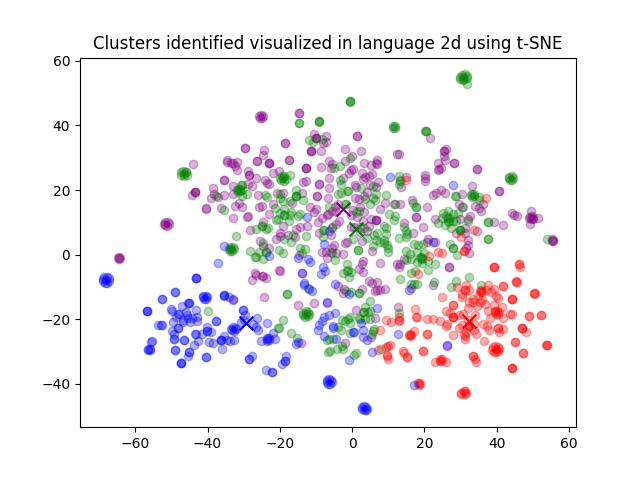
7.2 2. 聚类中的文本样本与聚类命名
我们将展示每个聚类中的随机样本。我们将使用qwen2-7b-instruct(注: 原文中是GPT-4)根据每个聚类中随机抽取的5条评论来命名聚类。
from openai import OpenAI
import os
OPENAI_API_BASE = os.environ.get("OPENAI_API_BASE")
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
client = OpenAI(api_key=OPENAI_API_KEY, base_url=OPENAI_API_BASE)
# Reading a review which belong to each group.
rev_per_cluster = 5
for i in range(n_clusters):
print(f"Cluster {i} Theme:", end=" ")
reviews = "\n".join(
df[df.Cluster == i]
.combined.str.replace("Title: ", "")
.str.replace("\n\nContent: ", ": ")
.sample(rev_per_cluster, random_state=42)
.values
)
messages = [
{
"role": "user",
"content": f'What do the following customer reviews have in common?\n\nCustomer reviews:\n"""\n{reviews}\n"""\n\nTheme:',
}
]
response = client.chat.completions.create(
model="qwen2-7b-instruct",
messages=messages,
temperature=0,
max_tokens=64,
top_p=1,
frequency_penalty=0,
presence_penalty=0,
)
print(response.choices[0].message.content.replace("\n", ""))
sample_cluster_rows = df[df.Cluster == i].sample(
rev_per_cluster, random_state=42
)
for j in range(rev_per_cluster):
print(sample_cluster_rows.Score.values[j], end=", ")
print(sample_cluster_rows.Summary.values[j], end=": ")
print(sample_cluster_rows.Text.str[:70].values[j])
print("-" * 100)输出结果如下:
Cluster
3 3.706186
2 4.144444
1 4.325658
0 4.467085
Name: Score, dtype: float64
Cluster 0 Theme: The customer reviews share a common theme of praising specific products for their health benefits, taste, and suitability for particular dietary needs, while also expressing dissatisfaction with pricing. Here's a breakdown:1. **Nutritional Value and Health Benefits**: The reviews highlight the positive aspects of the products in terms of nutrition, such as the
5, Yum!: I loved the V8 Pomegranate Blueberry energy drink! It was very good an
5, Michael Seasons Unsalted Potato Chips: These are the best chips ever! They are unsalted and being on a low s
5, Licorice for the Gluten Free: It is a very good tasting alternative to other licorice. Being Gluten
5, Michael Seasons Unsalted Potato Chips: These are the best chips ever! They are unsalted and being on a low s
3, This price is ridiculous!: There's nothing wrong with variety, except when it comes at too high a
----------------------------------------------------------------------------------------------------
Cluster 1 Theme: The common theme among these customer reviews is that they all express satisfaction with the product, despite some minor issues or preferences. Each review highlights a positive aspect of the product, such as flavor, taste, or overall satisfaction, while also mentioning a slight drawback or a desire for improvement. The reviewers seem to be repeat customers who
4, Like this tea: This tea has a nice flavor although I wish it was a little stronger.
5, Love this stuff!!: I Have been ordering this k cup cappucino drink for awhile now and hav
5, Addictive: I never cared much for the original Cherry Coke, but I love the new Ch
4, Like this tea: This tea has a nice flavor although I wish it was a little stronger.
2, twice the price of my expensive grocery store!: I know what I am getting as far as product, taste, etc., love the PRIM
----------------------------------------------------------------------------------------------------
Cluster 2 Theme: The common theme among these customer reviews is the evaluation and comparison of various coffee and tea products, particularly those designed for Keurig single-serve coffee makers. The reviewers discuss the quality, taste, value, and convenience of the products, often contrasting them with other options on the market, such as traditional K-Cups
5, Exactly what I was looking for: Fast, fantastic Chai!: I was skeptical as to how good an all-in-one Chai Tea for Keurig could
5, THE Alternative To High Priced K-Cups You've Been LOOKING For!: You love K-Cups, but get annoyed with paying $1.50+ apiece? This produ
5, Delish!!: So yummy... Drinking it Black coffee or w cream this coffee is delish
5, Good coffee.: This is the best Donut Shop Blend out there. Though most k-cups taste
1, way too bitter: I love coffee. I am used to strong coffee, I have lots of it. I drink
----------------------------------------------------------------------------------------------------
Cluster 3 Theme: The common theme among these customer reviews is the discrepancy between the product description and the actual product received, leading to dissatisfaction or disappointment among the reviewers. Each review highlights a different product and issue, but the core concern revolves around misrepresentation or misunderstanding of what the product entails. This theme is evident in the following aspects:1
5, Favorite chew toy!: This is the second one of these antlers that I've ordered (the first o
2, Contains aspartame!: I ordered this gum based on the premise that it contained xylitol rath
5, won't kid you: I won't kid you there is nothing better than a real hot dog. I love h
5, Dogs love it.: This is the "all gone" treat after dinner. It's the only treat that t
1, Deceptive description: On Oct 9 I ordered from a different vendor the same product 1.2 oz- 6
----------------------------------------------------------------------------------------------------大致内容如下:
Cluster 0 主题:这些客户评价的共同主题是对特定产品的健康益处、口味以及适合特定饮食需求的赞扬,同时对价格表示不满。以下是详细说明:
- 营养价值和健康益处:评论强调了产品在营养方面的积极方面,例如……
- 5星,Yum!:我喜欢V8石榴蓝莓能量饮料!它非常好……
- 5星,Michael Seasons 无盐薯片:这些是最棒的薯片!它们无盐,适合低钠饮食……
- 5星,无麸质甘草糖:它是其他甘草糖的很好替代品。因为无麸质……
- 5星,Michael Seasons 无盐薯片:这些是最棒的薯片!它们无盐,适合低钠饮食……
- 3星,这价格太荒谬了!:除了高价之外,品种丰富也没什么不对……
Cluster 1 主题:这些客户评价的共同主题是他们对产品表示满意,尽管存在一些小问题或偏好。每个评价都突出了产品的积极方面,如味道、口味或总体满意度,同时也提到了轻微的不足或改进的愿望。评价者似乎是回头客……
- 4星,喜欢这茶:这茶味道不错,但我希望它能再浓一点……
- 5星,爱这东西!:我已经点购这个K杯卡布奇诺饮料有一阵子了……
- 5星,令人上瘾:我以前不太喜欢原版樱桃可乐,但我爱上了新版……
- 4星,喜欢这茶:这茶味道不错,但我希望它能再浓一点……
- 2星,比我贵的杂货店贵两倍!:我知道我买的是产品、口味等,喜欢PRIM……
Cluster 2 主题:这些客户评价的共同主题是对各种咖啡和茶产品的评估和比较,尤其是为Keurig单杯咖啡机设计的产品。评价者讨论了产品的质量、口味、价值和便利性,常常与市场上的其他选项如传统K杯作比较……
- 5星,完全符合我的期望:快速、绝佳的印度奶茶!:我对Keurig的全自动印度奶茶是否能做好感到怀疑……
- 5星,你寻找已久的高价K杯的替代品!:你喜欢K杯,但讨厌每个要付1.50美元以上的价格?这个产品……
- 5星,太美味了!!:非常好喝……不管是黑咖啡还是加奶油都很好喝……
- 5星,好咖啡。:这是最好的甜甜圈店混合咖啡。虽然大多数K杯……
- 1星,太苦了::我喜欢咖啡,我习惯喝浓咖啡,喝很多……
Cluster 3 主题:这些客户评价的共同主题是产品描述与实际收到的产品之间的差异,导致了评论者的失望或不满。每个评论都突出不同的产品和问题,但核心关注点在于产品的误导或误解。这一主题在以下几个方面表现得很明显:
- 5星,最喜欢的咬咬玩具!:这是我订购的第二个这样的鹿角(第一个……
- 2星,含有阿斯巴甜!:我在基于该口香糖含有木糖醇而不是阿斯巴甜的前提下订购了它……
- 5星,我不会骗你::我不会骗你,没有什么比真正的热狗更好。我喜欢……
- 5星,狗狗们喜欢它。:这是晚餐后“吃光光”的奖励。这是唯一的奖励……
- 1星,欺骗性的描述::我在10月9日从不同的供应商那里订购了相同的产品……
需要注意的是,聚类结果不一定完全符合你的预期用途。更多的聚类数量将关注更具体的模式,而较少的聚类数量通常关注数据中最大的差异
8. 使用嵌入进行语义文本搜索
我们可以通过将搜索查询嵌入,然后找到最相似的评论,以非常高效且低成本的方式进行所有评论的语义搜索。
def test_semantic_text_search_using_embeddings():
import pandas as pd
import numpy as np
from ast import literal_eval
datafile_path = "data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["embedding"] = df.embedding.apply(literal_eval).apply(np.array)我们计算查询和文档嵌入之间的余弦相似度,并显示前 n 个最佳匹配。
cosine_similarity函数定义:
import numpy as np
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))search_reviews()函数定义:
from openai_embedding_sample import get_embedding, cosine_similarity
# search through the reviews for a specific product
def search_reviews(df, product_description, n=3, pprint=True):
product_embedding = get_embedding(product_description, model="bge-large-en-v1.5")
df["similarity"] = df.embedding.apply(
lambda x: cosine_similarity(x, product_embedding)
)
results = (
df.sort_values("similarity", ascending=False)
.head(n)
.combined.str.replace("Title: ", "")
.str.replace("; Content:", ": ")
)
if pprint:
for r in results:
print(r[:200])
print()
return resultstest_semantic_text_search_using_embeddings:
def test_semantic_text_search_using_embeddings():
import pandas as pd
import numpy as np
from ast import literal_eval
datafile_path = "data/fine_food_reviews_with_embeddings_1k.csv"
df = pd.read_csv(datafile_path)
df["embedding"] = df.embedding.apply(literal_eval).apply(np.array)
results = search_reviews(df, "delicious beans", n=3)
print(results)输出:
pytest -rP tests/test_openai.py::test_semantic_text_search_using_embeddings
Delicious!: I enjoy this white beans seasoning, it gives a rich flavor to the beans I just love it, my mother in law didn't know about this Zatarain's brand and now she is traying different seasoning
Delicious: While there may be better coffee beans available, this is my first purchase and my first time grinding my own beans. I read several reviews before purchasing this brand, and am extremely
Good Buy: I liked the beans. They were vacuum sealed, plump and moist. Would recommend them for any use. I personally split and stuck them in some vodka to make vanilla extract. Yum!
381 Delicious!: I enjoy this white beans seasonin...
159 Delicious: While there may be better coffee b...
442 Good Buy: I liked the beans. They were vacuum...
Name: combined, dtype: object