Rook是一个开源的云原生存储编排器,为Ceph存储提供平台、框架和支持,使其能够与云原生环境进行本地集成。Ceph是一个分布式存储系统,提供文件(file)、块(block)和对象存储(object storage),并在大规模生产集群中部署。
使用Rook可以自动部署和管理Ceph,提供自我管理、自我扩展和自我修复的存储服务。Rook Operator通过Kubernetes Resources来部署(deploy)、配置(configure)、供应(provision)、扩展(scale)、升级(upgrade)和监控(monitor)Ceph。
Rook 1.13开始移除了对Ceph Pacific (v16)的支持,而只支持Ceph Quincy (v17) and Ceph Reef (v18)。本文将实践使用Rook 1.13部署和管理Ceph(Reef) 18.2.1。
1.准备
1.1 K8S集群准备
Rook 1.13支持Kubernetes v1.23或更高版本。
本文使用的Kubernetes集群如下:
kubectl get node
NAME STATUS ROLES AGE VERSION
node4 Ready control-plane,edge 20h v1.29.0
node5 Ready <none> 20h v1.29.0
node6 Ready <none> 20h v1.29.0关于容器运行时的配置,这里的Kubernetes集群的容器运行时是Containerd。
注意如果Containerd的systemd配置containerd.service中如果有LimitNOFILE=infinity的配置,后边在使用rook启动Ceph集群时,Ceph的Mon组件会有问题,会出现ms_dispatch进程的cpu一直是100%,Rook社区有两个ISSUES ISSUE 11253和ISSUE 10110讨论了这个问题,需要将LimitNOFILE设置一个合适的值,我这里设置的是1048576。
1.2 设置各个服务器节点的时间同步
注意设置各个服务器节点的时间同步,这个十分重要,否则如果各个服务器节点时间不同步时,rook ceph operator在操作时,ceph mon组件的可能会无法正常工作。
关于时间同步推荐使用chronyd。
1.3 本地存储准备(LVM逻辑卷)
要配置Ceph存储集群,至少需要以下其中一种本地存储:
- 原始设备(Raw devices)(无分区或格式化文件系统)
- 原始分区(Raw partitions)(无格式化文件系统)
- LVM逻辑卷(无格式化文件系统)
- 以块模式(block mode)在存储类(storage class)中提供的持久卷。
本文将使用的本地存储是LVM逻辑卷。
本文中node4, node5, node6三台主机上都有一个未分区的本地磁盘将用作Ceph集群的本地存储。
fdisk -l | grep /dev/vdc
Disk /dev/vdc: 50 GiB, 53687091200 bytes, 104857600 sectors注意:在执行以下步骤之前,请确保磁盘上没有重要数据,因为这些步骤将擦除磁盘上的所有数据。
首先创建物理卷(Physical Volume),将磁盘/dev/vdc标记为物理卷。运行以下命令:
pvcreate /dev/vdc
Physical volume "/dev/vdc" successfully created.查看创建的物理卷:
pvdisplay
"/dev/vdc" is a new physical volume of "50.00 GiB"
--- NEW Physical volume ---
PV Name /dev/vdc
VG Name
PV Size 50.00 GiB
Allocatable NO
PE Size 0
Total PE 0
Free PE 0
Allocated PE 0
PV UUID AFIwMS-iAJZ-Od1w-dQ0a-1fdY-gg13-CcNo3a接下来创建名称为ceph的卷组(Volume Group),并将物理卷/dev/vdc添加到该卷组中:
vgcreate ceph /dev/vdc
Volume group "ceph" successfully created查看卷组:
vgdisplay
--- Volume group ---
VG Name ceph
System ID
Format lvm2
Metadata Areas 1
Metadata Sequence No 1
VG Access read/write
VG Status resizable
MAX LV 0
Cur LV 0
Open LV 0
Max PV 0
Cur PV 1
Act PV 1
VG Size <50.00 GiB
PE Size 4.00 MiB
Total PE 12799
Alloc PE / Size 0 / 0
Free PE / Size 12799 / <50.00 GiB
VG UUID lmU0uU-iI0q-zM9B-2wCQ-fWNs-eGF6-65oJLp最后从卷组ceph创建逻辑卷, 使用lvcreate命令来创建逻辑卷。指定卷组的名称、逻辑卷的名称、大小等参数:
lvcreate -n osd -l 100%FREE ceph
Logical volume "osd" created.上面的命令使用卷组ceph的所有可用空间创建了名称为osd的逻辑卷,如果想指定逻辑卷的具体大小可以使用下面的命令:
lvcreate -n osd -L 25G ceph因为Ceph集群所需要的本地存储是未格式化为文件系统的LVM逻辑卷,所以注意一定不要使用mkfs.ext4或mkfs.xfs格式化逻辑卷。
最后查看一下逻辑卷:
lvdisplay
--- Logical volume ---
LV Path /dev/ceph/osd
LV Name osd
VG Name ceph
LV UUID X1AuOK-1hXv-8I0M-dqrw-yMc2-a4XS-qnMUoN
LV Write Access read/write
LV Status available
# open 0
LV Size <50.00 GiB
Current LE 12799
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:02.部署Rook Operator
本文使用的Kubernetes集群只有node4~node6这3个节点, Ceph集群的各个组件混部在这3个节点上,对于更多节点的生产级别配置,可以对label做更精细化的配置,例如node-role.kubernetes.io/ceph-mon=ceph-mon等等。
这里将三个节点都打上role=ceph的label:
kubectl label nodes node4 role=ceph
kubectl label nodes node5 role=ceph
kubectl label nodes node6 role=ceph我们将通过使用Rook Helm Chart来部署rook ceph operator。
Rook目前将Ceph Operator的构建版本发布到发布(release)和主要(master)通道。发布通道是Rook的最新稳定版。
helm repo add rook-release https://charts.rook.io/release
helm install --create-namespace --namespace rook-ceph rook-ceph rook-release/rook-ceph -f values.yaml或者从https://charts.rook.io/release/rook-ceph-v1.13.1.tgz下载rook-ceph的helm chart,再使用下面的命令安装:
helm install --create-namespace --namespace rook-ceph rook-ceph rook-ceph-v1.13.1.tgz -f values.yaml关于values.yaml中配置的内容,可以根据文档https://github.com/rook/rook/blob/master/deploy/charts/rook-ceph-cluster/values.yaml中的内容按需定制。
以下是当前我所定制的内容,主要配置了在部署Rook Operator和Ceph时使用私有的镜像仓库地址,以及调度相关的配置。
image:
pullPolicy: IfNotPresent
repository: registry.frognew.com/library/rook/ceph
tag: v1.13.1
imagePullSecrets:
- name: regsecret
tolerations:
- key: "dedicated"
operator: "Equal"
value: "ceph"
effect: "NoSchedule"
provisionerNodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- ceph
provisionerTolerations:
- key: "dedicated"
operator: "Equal"
value: "ceph"
effect: "NoSchedule"
pluginNodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- ceph
pluginTolerations:
- key: "dedicated"
operator: "Equal"
value: "ceph"
effect: "NoSchedule"
discover:
tolerations:
- key: "dedicated"
operator: "Equal"
value: "ceph"
effect: "NoSchedule"
nodeAffinity:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- ceph
admissionController:
tolerations:
- key: "dedicated"
operator: "Equal"
value: "ceph"
effect: "NoSchedule"
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "PreferNoSchedule"
nodeAffinity:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- ceph
csi:
kubeletDirPath: /var/lib/kubelet
cephcsi:
# -- Ceph CSI image
# @default -- `quay.io/cephcsi/cephcsi:v3.10.1``
image: registry.frognew.com/gcr/quay.io/cephcsi/cephcsi:v3.10.1
registrar:
# -- Kubernetes CSI registrar image
# @default -- `registry.k8s.io/sig-storage/csi-node-driver-registrar:v2.9.1`
image: registry.frognew.com/gcr/registry.k8s.io/sig-storage/csi-node-driver-registrar:v2.9.1
provisioner:
# -- Kubernetes CSI provisioner image
# @default -- `registry.k8s.io/sig-storage/csi-provisioner:v3.6.2`
image: registry.frognew.com/gcr/registry.k8s.io/sig-storage/csi-provisioner:v3.6.2
snapshotter:
# -- Kubernetes CSI snapshotter image
# @default -- `registry.k8s.io/sig-storage/csi-snapshotter:v6.3.2`
image: registry.frognew.com/gcr/registry.k8s.io/sig-storage/csi-snapshotter:v6.3.2
attacher:
# -- Kubernetes CSI Attacher image
# @default -- `registry.k8s.io/sig-storage/csi-attacher:v4.4.2`
image: registry.frognew.com/gcr/registry.k8s.io/sig-storage/csi-attacher:v4.4.2
resizer:
# -- Kubernetes CSI resizer image
# @default -- `registry.k8s.io/sig-storage/csi-resizer:v1.9.2`
image: registry.frognew.com/gcr/registry.k8s.io/sig-storage/csi-resizer:v1.9.2https://github.com/rook/rook/blob/master/deploy/examples/images.txt这个地址里面有部署Rook Operator和Ceph所需的所有容器镜像,可以根据需要预先同步到我们的私有镜像仓库中。
本文中用到的镜像如下:
rook/ceph:1.13.1
quay.io/ceph/ceph:v18.2.1
quay.io/cephcsi/cephcsi:v3.10.1
quay.io/csiaddons/k8s-sidecar:v0.8.0
registry.k8s.io/sig-storage/csi-attacher:v4.4.2
registry.k8s.io/sig-storage/csi-node-driver-registrar:v2.9.1
registry.k8s.io/sig-storage/csi-provisioner:v3.6.2
registry.k8s.io/sig-storage/csi-resizer:v1.9.2
registry.k8s.io/sig-storage/csi-snapshotter:v6.3.2部署完成后,确认rook-ceph-operator的正常启动:
kubectl get pods -n rook-ceph -l "app=rook-ceph-operator"
NAME READY STATUS RESTARTS AGE
rook-ceph-operator-764755b6f4-8z2vb 1/1 Running 0 3m6s3.创建Ceph集群
3.1 参考文档
Rook文档侧重于在各种环境中启动Rook。在创建Ceph集群时,可以考虑在以下的示例集群清单基础上做定制:
- cluster.yaml:用于在裸机上运行的生产集群的集群设置。需要至少三个工作节点。
- cluster-on-pvc.yaml:用于在动态云环境中运行的生产集群的集群设置。
- cluster-test.yaml:用于测试环境(如 minikube)的集群设置。
有关更多详细信息,可参考Ceph的示例配置。
Rook Ceph Operator已经部署完成并正常运行,我们可以创建Ceph集群了,这里选择的是cluster.yaml。
3.2 创建集群
基于cluster.yaml定制我们自己的cluster.yaml,以下是只包含cluster.yaml的修改内容:
...
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
name: rook-ceph
namespace: rook-ceph
spec:
cephVersion:
image: registry.frognew.com/gcr/quay.io/ceph/ceph:v18.2.1
...
dashboard:
enabled: true
ssl: false
...
storage:
useAllNodes: true
useAllDevices: true
devices:
- name: /dev/disk/by-id/dm-name-ceph-osd
config:
osdsPerDevice: "1"
...
placement:
all:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: role
operator: In
values:
- ceph
podAffinity:
podAntiAffinity:
topologySpreadConstraints:
tolerations:
- key: "dedicated"
operator: "Equal"
value: "ceph"
effect: "NoSchedule"
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "PreferNoSchedule"
...因为Ceph集群的本地存储将使用前面创建的未格式化文件系统的LVM逻辑卷,我们创建的逻辑卷的名称为osd,所属的卷组为ceph,逻辑卷的路径为/dev/ceph/osd。
Rook是从1.9开始支持使用LVM逻辑卷作为本地存储的,具体实现的代码是这个PR https://github.com/rook/rook/pull/7967。
文档CephCluster CRD中对如何使用逻辑卷作存储的说明不是特别详细。从PR的实现代码上看,当前是要在CephCluster的资源定义中的spec.storage.devices[].name配置为/dev/disk/by-id/dm-name-<vgName>-<lvName>。
所以我们的cluster.yaml配置的spec.storage部分, devices[].name的值是/dev/disk/by-id/dm-name-ceph-osd。
创建Ceph集群:
kubectl create -f cluster.yaml
cephcluster.ceph.rook.io/rook-ceph created通过查看rook-ceph命名空间中的pod,验证集群是否正在运行。
kubectl get po -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-dfb8v 2/2 Running 0 39m
csi-cephfsplugin-jf7z2 2/2 Running 0 39m
csi-cephfsplugin-mmkzb 2/2 Running 0 39m
csi-cephfsplugin-provisioner-854577c67d-6279q 5/5 Running 0 39m
csi-cephfsplugin-provisioner-854577c67d-q28kf 5/5 Running 0 39m
csi-rbdplugin-provisioner-6746f78f6c-2p9hg 5/5 Running 0 39m
csi-rbdplugin-provisioner-6746f78f6c-zrfb9 5/5 Running 0 39m
csi-rbdplugin-sbf2n 2/2 Running 0 39m
csi-rbdplugin-v9t9l 2/2 Running 0 39m
csi-rbdplugin-xbk9t 2/2 Running 0 39m
rook-ceph-crashcollector-node4-55fc679d6-sd58j 1/1 Running 0 27m
rook-ceph-crashcollector-node5-5bbb5d47f5-x5bwz 1/1 Running 0 28m
rook-ceph-crashcollector-node6-67dcd465b8-qs5tj 1/1 Running 0 27m
rook-ceph-exporter-node4-7f7945dfc8-6t9lb 1/1 Running 0 27m
rook-ceph-exporter-node5-5cd544f579-hpjv8 1/1 Running 0 28m
rook-ceph-exporter-node6-6f4c7f94d8-88c6k 1/1 Running 0 27m
rook-ceph-mgr-a-684b555c96-x9r5g 3/3 Running 0 28m
rook-ceph-mgr-b-d48786cdf-g8hf4 3/3 Running 0 28m
rook-ceph-mon-a-6df558b49f-mjnfg 2/2 Running 0 29m
rook-ceph-mon-b-6dd9d9dd8f-2qtrn 2/2 Running 0 29m
rook-ceph-mon-c-7f9d9c6887-msmcw 2/2 Running 0 29m
rook-ceph-operator-764755b6f4-8z2vb 1/1 Running 0 57m
rook-ceph-osd-0-8fc549b78-l6jgd 2/2 Running 0 27m
rook-ceph-osd-1-86798fbd89-hbsxj 2/2 Running 0 27m
rook-ceph-osd-2-76ffbb6886-sv986 2/2 Running 0 27m
rook-ceph-osd-prepare-node4-lkwsv 0/1 Completed 0 25m
rook-ceph-osd-prepare-node5-bt7fn 0/1 Completed 0 25m
rook-ceph-osd-prepare-node6-vvkk9 0/1 Completed 0 25mosd pod的数量取决于集群中的节点数量和配置的设备数量。对于上述默认的cluster.yaml,将为每个节点上找到的每个可用设备创建一个OSD。
创建过程如果遇到问题可以查看rook-ceph-operator的Pod的日志。
如需重新运行rook-ceph-osd-prepare-<nodename> Job,扫描可用本地存储添加OSD,可以执行以下命令:
# 删除旧的job
kubectl get job -n rook-ceph | awk '{system("kubectl delete job "$1" -n rook-ceph")}'
# 重启operator
kubectl rollout restart deploy rook-ceph-operator -n rook-ceph每个节点上的osd能否添加成功,要注意查看rook-ceph-osd-prepare-<nodename> Job对应Pod的日志。
4.验证集群状态
为了验证集群处于健康状态, 需要Rook工具箱。
kubectl apply -f https://raw.githubusercontent.com/rook/rook/release-1.13/deploy/examples/toolbox.yaml
kubectl get po -n rook-ceph | grep rook-ceph-tools
rook-ceph-tools-68b98695bb-gh76t 1/1 Running 0 23s注: 当前release-1.13/deploy/examples/toolbox.yaml中的Ceph镜像还是v17.2.6,可以手动修改成v18.2.1
连接到工具箱,并运行ceph status 命令:
kubectl -n rook-ceph exec -it deploy/rook-ceph-tools -- bash以下是健康状态的验证要点:
- 所有的 monitor (mon) 节点应该处于 quorum(一致性)状态。
- 一个管理器 (mgr) 节点应该处于活动状态。
- 至少有三个 OSD 节点应该处于上线并可用状态。
如果健康状态不是 HEALTH_OK,则应该调查警告或错误的原因。
ceph status
cluster:
id: aea4b99c-7ae3-4ac9-ba1b-ff3ecc49ec51
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 33m)
mgr: b(active, since 31m), standbys: a
osd: 3 osds: 3 up (since 31m), 3 in (since 33m)
data:
pools: 1 pools, 1 pgs
objects: 2 objects, 449 KiB
usage: 81 MiB used, 150 GiB / 150 GiB avail
pgs: 1 active+clean从输出可以看出集群状态一切正常,集群中部署了3个mon, 2个mgr, 3个osd。
查看一下当前集群中的存储池:
ceph osd lspools
1 .mgr可以看到当前集群中只有一个名称为.mgr的存储池。这表示在这个Ceph集群中只创建了默认的管理池(mgr pool),这是一个特殊的池,用于存储管理和监控相关的数据。
4.使用存储
Ceph提供三种类型的存储接口: 块存储(Block)、共享文件系统(Shared Filesystem)、对象存储(Object)。
下面演示对于使用Rook部署和管理的Ceph集群,如何使用这三种存储。
通过Rook使用Ceph提供的三种存储类型以及它们的用途如下:
- 块存储(Block)适用于为单个 Pod 提供读写一致性(RWO)的存储
- CephFS 共享文件系统(Shared Filesystem)适用于多个Pod之间共享读写(RWX)的存储
- 对象存储(Object)提供了一个可通过内部或外部的Kubernetes集群的S3端点访问的存储
使用存储的详细内容这里略过,具体可查看之前编写的Rook 1.11部署指南中的"使用存储"。
5.Ceph Dashboard
通过使用Ceph Dashboard可以查看集群的状态。使用Rook部署的Ceph集群已经默认启用了Ceph Dashboard。
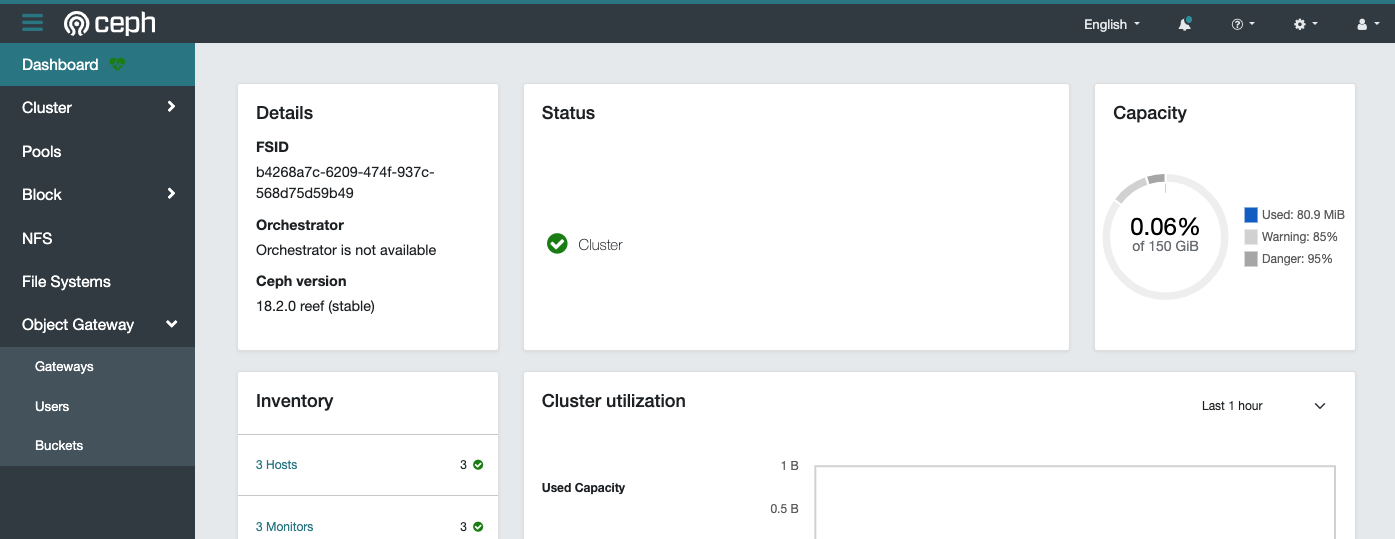
rook-ceph-mgr-dashboard是其在Kubernetes集群中的Service:
kubectl get svc rook-ceph-mgr-dashboard -n rook-ceph
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr-dashboard ClusterIP 10.111.14.238 <none> 7000/TCP 35m可通过Ingress或创建一个NodePort的Service dashboard-external-http将其暴露的Kubernetes集群外部。
Ceph Dashboard admin用户的命名可以通过下面的命令查看:
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo