1.备份特性(backup features)
1.1 LRU dump backup
Percona XtraBackup在备份中包含了一个已保存的缓冲池转储,以便减少预热时间。在重新启动后,它可以从ib_buffer_pool文件中还原缓冲池状态。Percona XtraBackup会自动检测并备份ib_buffer_pool。
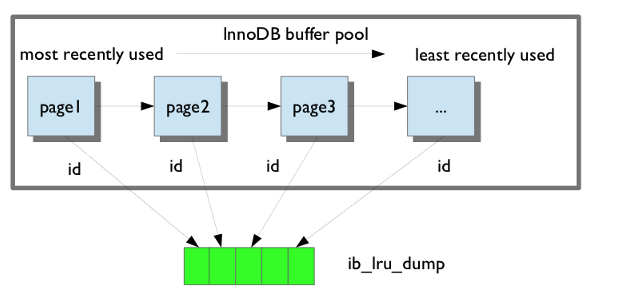
如果在my.cnf中启用了缓冲池恢复选项,备份恢复后缓冲池将处于预热状态。
1.2 限制备份速度(Throttling backups)
尽管xtrabackup不会阻止数据库的操作,但任何备份都可能会给被备份的系统增加负载。在没有太多闲置I/O容量的系统上,限制xtrabackup读写数据的速率可能会有所帮助。可以使用--throttle选项来实现这一点。该选项限制了每秒复制的数据块数。每个块的大小为10MB。
下面的图片展示了当--throttle设置为1时限速的工作方式。
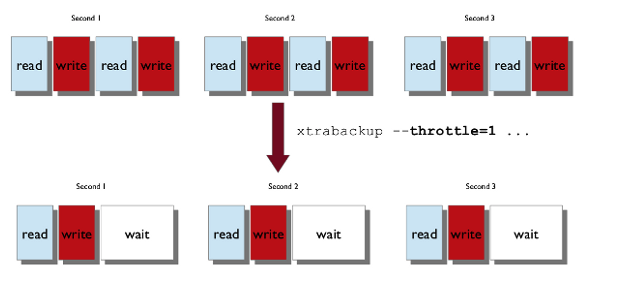
当与--backup选项一起使用时,此选项限制了xtrabackup每秒执行的读写操作对数。如果正在创建增量备份,则限制是每秒读取的I/O操作数。
默认情况下,没有限制,xtrabackup会尽可能快地读写数据。如果设置了过于严格的IOPS限制,备份可能会变得非常慢,以至于无法赶上InnoDB正在写入的事务日志,因此备份可能永远无法完成。
1.3 在服务器上存储备份历史记录
Percona XtraBackup支持在服务器上存储备份历史记录。这个功能在Percona XtraBackup 2.2中实现。存储备份历史记录在服务器上是为了为用户提供关于正在进行的备份的附加信息。备份历史信息将存储在PERCONA_SCHEMA.XTRABACKUP_HISTORY表中。
要使用这个功能,有以下选项可用:
--history= :此选项启用历史记录功能,并允许用户指定一个备份系列名称,该名称将放置在历史记录中。--incremental-history-name= :此选项允许基于特定历史系列进行增量备份,使用名称进行标识。xtrabackup将在历史表中查找最近的(最高to_lsn)系列中的备份,并将to_lsn值作为其起始LSN。这与--incremental-history-uuid、--incremental-basedir和--incremental-lsn选项互斥。如果找不到有效的LSN(没有该名称的系列),xtrabackup将返回错误。--incremental-history-uuid= :允许基于特定UUID进行增量备份的历史记录。xtrabackup将在历史表中查找与UUID匹配的记录,并将to_lsn值作为其起始LSN。这个选项与--incremental-basedir、--incremental-lsn和--incremental-history-name选项互斥。如果找不到有效的LSN(没有该UUID的记录或缺少to_lsn),xtrabackup 将返回错误。
当前正在执行的备份不会存在于生成的备份集中的
xtrabackup_history表中,因为记录将在备份完成之后才会添加到该表中。
如果你希望在发生灾难性事件时能够在备份集之外访问备份历史记录,你需要在xtrabackup完成后执行mysqldump、部分备份或对历史记录表执行SELECT *操作,并将结果与你的备份集一起存储。
PERCONA_SCHEMA.XTRABACKUP_HISTORY
该表包含有关先前服务器备份的信息。仅在使用--history选项进行备份时,才会写入关于备份的信息。
| Column Name | Description |
|---|---|
| uuid | 唯一备份标识符 |
| name | 用户提供的备份系列名称。可能会有多个具有相同名称的条目,用于标识系列中相关的备份。 |
| tool_name | 用于进行备份的工具的名称。 |
| tool_command | 用于工具的精确命令行,其中包括 –password 和 –encryption_key 的加密。 |
| tool_version | 用于进行备份的工具的版本。 |
| ibbackup_version | 用于进行备份的 xtrabackup 二进制文件的版本。 |
| server_version | 进行备份的服务器版本。 |
| start_time | 备份开始的时间。 |
| end_time | 备份结束的时间。 |
| lock_time | 调用并保持 FLUSH TABLES WITH READ LOCK 以获取锁的时间,以秒为单位。 |
| binlog_pos | FLUSH TABLES WITH READ LOCK 结束时的 binlog 文件和位置。 |
| innodb_from_lsn | 备份开始时的 LSN,可用于确定之前的备份。 |
| innodb_to_lsn | 备份结束时的 LSN,可用作下一个增量备份的起始 LSN。 |
| partial | 是否为部分备份,如果是 N,则表示为完整备份。 |
| incremental | 是否为增量备份。 |
| format | 结果格式的描述(xbstream)。 |
| compact | 是否为紧凑备份。 |
| compressed | 是否为压缩备份。 |
| encrypted | 是否为加密备份。 |
限制条件
--history选项必须仅在命令行中指定,不能在配置文件中指定,以使其生效。
--incremental-history-name和--incremental-history-uuid选项必须仅在命令行中指定,不能在配置文件中指定,以使其生效。
2.准备特性(prepare features)
2.1 字典缓存
Percona XtraBackup基于崩溃恢复的工作原理。Percona XtraBackup复制InnoDB数据文件,从而产生了内部不一致的数据;然后,在准备(prepare)阶段对文件执行崩溃恢复,以使其成为一致的、可用的数据库。
--prepare阶段有以下操作:
- 应用redo log
- 应用undo log
作为物理操作,redo log修改的更改会应用到y一个页(page)上。在重做日志操作中,没有行或事务的概念。重做应用操作不会使数据库与事务一致。未提交的事务可以由服务器刷新或写入redo log。Percona XtraBackup应用在redo中记录的更改。
在应用redo log时,Percona XtraBackup在表空间(IBD文件)中的特定偏移量上进行物理修改。
作为逻辑操作,Percona XtraBackup在特定行上应用undo log。当redo log完成时,XtraBackup使用撤undo log来回滚备份期间未提交事务的更改。
undo log
有两种类型的undo log:
- INSERT
- UPDATE
undo log记录包含一个table_id。Percona XtraBackup使用此table_id来查找表定义,然后使用该信息来解析索引页面上的记录。事务回滚读取undo log记录并应用更改。
在初始化数据字典引擎和数据字典缓存之后,存储引擎可以请求table_id,并使用此ID获取表模式。索引搜索元组tuple(键)是从表模式和undo日志记录的键字段创建的。服务器使用搜索元组(键)找到记录并执行撤销操作。
例如,InnoDB使用table_id(也称为se_private_id)作为表定义。Percona XtraBackup不像服务器那样运行,并且无法访问数据字典。XtraBackup在需要时初始化InnoDB引擎并使用InnoDB表对象(dict_table_t)。XtraBackup依赖于存储在表空间中的序列化字典信息(SDI)。SDI是表的JSON表示。
版本变动
在Percona XtraBackup 8.0.33-28 之前,XtraBackup将SDI从每个 .IBD 文件和所有表加载到缓存中,作为不可淘汰的。将表设为不可淘汰实质上是禁用了LRU缓存。每个表都会一直保留在内存中,直到操作结束。
这种方法存在以下问题:
- 从读取SDI页面以加载不需要进行回滚的表导致不必要的IO操作
- 将所有表加载到缓存中增加了`–prepare阶段所需的时间
- 不必要的表可能导致内存溢出错误
- 大量的表和IBD文件可能会在
--prepare阶段导致退出
Percona XtraBackup 8.0.33-28实现了一种新的设计,表被加载为可淘汰的。XtraBackup扫描数据字典表mysql.indexes和mysql.index_partitions的B-Tree索引,以建立table_id与表空间(space_id)之间的关系。在事务回滚期间,XtraBackup使用这个关系。XtraBackup仅在表上有事务回滚时才加载用户表。
当达到缓存大小限制时,后台线程或Percona XtraBackup 主线程会处理缓存淘汰。
这个新的设计在--prepare阶段提供了以下好处:
- 使用更少的内存
- 使用更少的 IO
- 提高了
--prepare阶段所需的时间 - 即使
--prepare阶段有大量的表,也能成功完成 - 更快地完成 Percona XtraDB Cluster SST 过程
3. 还原特性(recovery)
3.1 时间点还原(Point-in-time recovery)
使用xtrabackup和服务器的二进制日志,可以恢复到数据库历史的特定时刻。
请注意,二进制日志包含从过去某个时间点开始修改数据库的操作。你需要一个完整的数据目录作为基础,然后可以通过将一系列操作从二进制日志中应用到数据上,使数据与你所需的特定时间点的状态匹配。
xtrabackup --backup --target-dir=/path/to/backup
xtrabackup --prepare --target-dir=/path/to/backup有关上面这些步骤的详细信息,请查看创建备份和准备备份相关文档。
现在,假设已经过了一段时间,你希望将数据库恢复到过去的某个特定时刻,同时要考虑到快照被拍摄的时间点的限制。
要了解服务器中二进制日志的情况,请执行以下查询:
mysql> SHOW BINARY LOGS;
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000001 | 126 |
| mysql-bin.000002 | 1306 |
| mysql-bin.000003 | 126 |
| mysql-bin.000004 | 497 |
+------------------+-----------+和
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000004 | 497 | | |
+------------------+----------+--------------+------------------+第一个查询将告诉你哪些文件包含二进制日志,而第二个查询将告诉你哪个文件当前正在用于记录更改,并显示其中的当前位置。这些文件通常存储在数据目录中(除非在使用--log-bin=选项启动服务器时指定了其他位置)。
要找出所拍摄快照的位置,请查看备份目录中的xtrabackup_binlog_info文件:
cat /path/to/backup/xtrabackup_binlog_info
mysql-bin.000003 57这将告诉你在备份时二进制日志使用的文件以及其位置。当你恢复备份时,该位置将是有效的位置:
xtrabackup --copy-back --target-dir=/path/to/backup由于还原不会影响二进制日志文件,下一步是使用mysqlbinlog从快照的位置开始提取二进制日志中的查询,并将其重定向到一个文件中:
mysqlbinlog /path/to/datadir/mysql-bin.000003 /path/to/datadir/mysql-bin.000004 \
--start-position=57 > mybinlog.sql请注意,如果你的二进制日志有多个文件,就像示例中一样,你必须使用一个进程提取查询,如上所示。
检查带有查询的文件,以确定哪个位置或日期对应于所需的时间点。确定后,将其导入服务器。假设时间点是11-12-25 01:00:00:
mysqlbinlog /path/to/datadir/mysql-bin.000003 /path/to/datadir/mysql-bin.000004 \
--start-position=57 --stop-datetime="11-12-25 01:00:00" | mysql -u root -p然后数据库将被还原到该时间点。
3.2 还原单独的表(Restore individual tables)
Percona XtraBackup可以导出一个包含在其自己的.ibd文件中的表。使用Percona XtraBackup,你可以从任何InnoDB数据库导出单个表,并将其导入到带有XtraDB的Percona Server for MySQL或MySQL 8.0中。源数据库不必是XtraDB或MySQL 8.0,但目标数据库必须是。这种方法只适用于单独的.ibd文件。
以下示例演示了导出和导入以下表:
CREATE TABLE export_test (
a int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;导出表
要在目标目录中生成一个.ibd文件,请使用innodb_file_per_table模式创建表:
find /data/backups/mysql/ -name export_test.*
/data/backups/mysql/test/export_test.ibd在--prepare步骤中,将--export选项添加到命令中。例如:
xtrabackup --prepare --export --target-dir=/data/backups/mysql/当恢复一个加密的InnoDB表空间表时,请添加密钥文件:
xtrabackup --prepare --export --target-dir=/tmp/table \
--keyring-file-data=/var/lib/mysql-keyring/keyring以下文件是将表导入运行Percona Server for MySQL with XtraDB或MySQL 8.0的服务器所需的唯一文件。如果服务器使用InnoDB表空间加密,请添加包含传输密钥和加密表空间密钥的.cfp文件。
这些文件位于目标目录中:
/data/backups/mysql/test/export_test.ibd
/data/backups/mysql/test/export_test.cfg导入表
在运行Percona Server for MySQL with XtraDB 或 MySQL 8.0的目标服务器上,创建一个具有相同结构的表,然后执行以下步骤:
运行
ALTER TABLE test.export_test DISCARD TABLESPACE;命令。如果你看到以下错误消息:ERROR 1809 (HY000): Table 'test/export_test' in system tablespace在服务器上启用
innodb_file_per_table选项,并重新创建表。set global innodb_file_per_table=ON;将导出的文件复制到目标服务器数据目录的
test/子目录中。运行
ALTER TABLE test.export_test IMPORT TABLESPACE;命令。表将被导入,并且你可以运行 SELECT 查询来查看导入的数据。
4.加密的InnoDB表空间备份
InnoDB支持对存储在文件表空间中的InnoDB表进行数据加密。这个特性为物理表空间数据文件提供了静止状态的加密。
对于已认证的用户或应用程序来访问加密的表空间,InnoDB使用主加密密钥来解密表空间密钥。主加密密钥存储在一个keyring中。xtrabackup支持两种keyring插件:keyring_file和keyring_vault。这些插件被安装到插件目录中。
由于目前没有用到加密备份功能,这里略过对这部分内容的学习…
5. FLUSH TABLES WITH READ LOCK选项
使用全局读锁(FLUSH TABLES WITH READ LOCK选项)会执行以下操作:
- 关闭所有已打开的表
- 锁定所有数据库的所有表
- 释放锁定,使用
UNLOCK TABLES。
FLUSH TABLES WITH READ LOCK选项不会阻止将行插入日志表。
为确保一致的备份,使用FLUSH TABLES WITH READ LOCK选项在进行非InnoDB文件备份之前。该选项不会影响长时间运行的查询。
启用FLUSH TABLES WITH READ LOCK时的长时间运行查询可能会使服务器处于只读模式,直到查询完成。如果数据库处于等待表刷新或等待主服务器发送事件状态,则终止FLUSH TABLES WITH READ LOCK不会有帮助。要返回正常操作,必须终止任何长时间运行的查询。
在使用备份锁时,此部分中的所有描述均不会生效。Percona XtraBackup将在支持的情况下使用备份锁,作为
FLUSH TABLES WITH READ LOCK的轻量级替代方案。此功能在Percona Server for MySQL 5.6+中可用。Percona XtraBackup会自动使用备份锁,以复制非InnoDB数据,以避免阻塞修改InnoDB表格的DML查询。
为了防止这种情况发生,已经实施了两个操作:
- xtrabackup等待良好的时机发出全局锁定
- xtrabackup终止所有查询,或者仅终止阻止获取全局锁定的SELECT查询
等待查询完成
在没有长时间查询运行时应发出全局锁定。等待在较长的时间内发出全局锁定不是一个好的方法。等待可以延长备份所需的时间。--ftwrl-wait-timeout选项可以限制等待时间。如果在此时间内无法发出锁定,则xtrabackup会停止选项,退出并显示错误消息,备份将不会执行。
此选项的默认值为0,即关闭该选项。
另一个可能性是指定要等待的查询类型。在这种情况下,使用--ftwrl-wait-query-type。可能的值是all和update。当使用all时,xtrabackup会等待所有长时间运行的查询(执行时间超过--ftwrl-wait-threshold允许的时间)完成后再运行FLUSH TABLES WITH READ LOCK。当使用update时,xtrabackup会等待UPDATE/ALTER/REPLACE/INSERT查询完成。
难以预测特定查询需要的完成时间。我们假设长时间运行的查询将不会及时完成。其他运行时间短的查询会迅速完成。xtrabackup使用--ftwrl-wait-threshold选项的值来指定长时间运行的查询,并会阻塞全局锁定。为了使用此选项,xtrabackup用户应具有PROCESS和SUPER权限。
终止阻止查询
第二个选项是终止阻止获取全局锁定的所有查询。在这种情况下,所有运行时间长于FLUSH TABLES WITH READ LOCK的查询都可能是潜在的阻止者。虽然所有查询都可以被终止,但可以为短时间运行的查询指定额外的时间以完成,使用--kill-long-queries-timeout选项。此选项指定查询完成的时间,在达到该值后,所有正在运行的查询将被终止。默认值为0,即关闭此功能。
--kill-long-query-type选项可用于指定阻止全局锁获取的所有或仅SELECT查询。为了使用此选项,xtrabackup用户应具有PROCESS和SUPER权限。
选项总结
- –ftwrl-wait-timeout(秒) - 等待良好时机的时间。默认值为0,表示不等待。
- –ftwrl-wait-query-type - 在运行
FLUSH TABLES WITH READ LOCK之前应完成哪些长时间查询。默认值为all。 - –ftwrl-wait-threshold(秒) - 查询在被视为长时间运行和潜在的全局锁阻塞器之前应运行多长时间。
- –kill-long-queries-timeout(秒) - 在发出
FLUSH TABLES WITH READ LOCK后的多长时间内查询将完成,然后开始终止。默认值为0,表示不终止。 - –kill-long-query-type - 在
kill-long-queries-timeout超时后,应终止哪些查询。
示例
使用以下选项运行xtrabackup将导致xtrabackup花费不超过3分钟的时间等待所有超过40秒的查询完成。
xtrabackup --backup --ftwrl-wait-threshold=40 \
--ftwrl-wait-query-type=all --ftwrl-wait-timeout=180 \
--kill-long-queries-timeout=20 --kill-long-query-type=all \
--target-dir=/data/backups/在发出FLUSH TABLES WITH READ LOCK之后,xtrabackup将等待20秒钟以获取锁。如果在20秒后仍未获取到锁定,则它将终止所有运行时间超过FLUSH TABLES WITH READ LOCK的查询。
6.改进的日志语句
Percona XtraBackup是一个开源的命令行实用程序。命令行工具与后台操作的交互有限,日志提供了操作的进度或有关错误的更多信息。
在早期版本中,错误日志没有标准的结构。请注意以下示例中日志语句的变化:
- 备份日志语句的头部包含了生成该语句的模块名称xtrabackup,但没有时间戳:
xtrabackup: recognized client arguments: --parallel=4 --target-dir=/data/backups/ --backup=1输出应该类似于以下内容:
./bin/xtrabackup version 8.0.27-19 based on MySQL server 8.0.27 Linux (x86_64) (revision id: b0f75188ca3)- copy-back日志语句包含时间戳但没有模块名称。时间戳是UTC和本地时区的混合。
220322 19:05:13 [01] Copying undo_001 to /data/backups/undo_001- 下面的prepare日志语句没有头部信息,这使得诊断问题变得更加困难。
Completed space ID check of 1008 files.
Initializing buffer pool, total size = 128.000000M, instances = 1, chunk size =128.000000M
Completed initialization of buffer pool
If the mysqld execution user is authorized, page cleaner thread priority can be changed. See the man page of setpriority().从Percona XtraBackup 8.0.28-20开始,已经对日志语句进行了改进。改进后的日志结构显示在backup, prepare, move-back/copy-back的错误日志中。
每个日志语句具有以下属性:
- Timestamp时间戳 - 表示事件发生的时间戳,采用UTC格式。
- Severity严重级别 - 语句的严重级别表示事件的重要性。
- ID - 这个标识符目前没有被使用,但在将来的版本中可能会被使用。
- Context上下文 - 发布日志语句的模块的名称,如XtraBackup、InnoDB或Server。
- Message消息 - 模块生成的事件描述。
以下是使用改进的结构生成的准备日志的示例。头部的一致性使得更容易跟踪操作的进度或者检查日志以诊断问题。
2022-03-22T19:15:36.142247+05:30 0 [Note] [MY-011825] [Xtrabackup] This target seems to be not prepared yet.
2022-03-22T19:15:36.142792+05:30 0 [Note] [MY-013251] [InnoDB] Number of pools: 1
2022-03-22T19:15:36.149212+05:30 0 [Note] [MY-011825] [Xtrabackup] xtrabackup_logfile detected: size=8388608, start_lsn=(33311656)
2022-03-22T19:15:36.149998+05:30 0 [Note] [MY-011825] [Xtrabackup] using the following InnoDB configuration for recovery:
2022-03-22T19:15:36.150023+05:30 0 [Note] [MY-011825] [Xtrabackup] innodb_data_home_dir = .
2022-03-22T19:15:36.150036+05:30 0 [Note] [MY-011825] [Xtrabackup] innodb_data_file_path = ibdata1:12M:autoextend
2022-03-22T19:15:36.150078+05:30 0 [Note] [MY-011825] [Xtrabackup] innodb_log_group_home_dir = .
2022-03-22T19:15:36.150095+05:30 0 [Note] [MY-011825] [Xtrabackup] innodb_log_files_in_group = 1
2022-03-22T19:15:36.150111+05:30 0 [Note] [MY-011825] [Xtrabackup] innodb_log_file_size = 8388608
2022-03-22T19:15:36.151667+05:30 0 [Note] [MY-011825] [Xtrabackup] inititialize_service_handles suceeded
2022-03-22T19:15:36.151903+05:30 0 [Note] [MY-011825] [Xtrabackup] using the following InnoDB configuration for recovery:
2022-03-22T19:15:36.151926+05:30 0 [Note] [MY-011825] [Xtrabackup] innodb_data_home_dir = .
2022-03-22T19:15:36.151954+05:30 0 [Note] [MY-011825] [Xtrabackup] innodb_data_file_path = ibdata1:12M:autoextend
2022-03-22T19:15:36.151976+05:30 0 [Note] [MY-011825] [Xtrabackup] innodb_log_group_home_dir = .
2022-03-22T19:15:36.151991+05:30 0 [Note] [MY-011825] [Xtrabackup] innodb_log_files_in_group = 1
2022-03-22T19:15:36.152004+05:30 0 [Note] [MY-011825] [Xtrabackup] innodb_log_file_size = 8388608
2022-03-22T19:15:36.152021+05:30 0 [Note] [MY-011825] [Xtrabackup] Starting InnoDB instance for recovery.
2022-03-22T19:15:36.152035+05:30 0 [Note] [MY-011825] [Xtrabackup] Using 104857600 bytes for buffer pool (set by --use-memory parameter)7.lock-ddl-per-table选项的改进
为了在实例上阻止DDL语句,Percona Server实现了LOCK TABLES FOR BACKUP。Percona XtraBackup在备份过程中使用此锁定。此锁不影响DML语句。
Percona XtraBackup还实现了--lock-ddl-per-table选项,通过使用元数据锁(MDL)来阻止DDL语句。
以下步骤描述了在使用--lock-ddl-per-table时进行的简化备份操作:
- 解析并复制检查点标记后的所有redo log
- fork一个专用线程来继续跟踪新的redo log条目
- 列出需要复制的表空间
- 遍历列表。对于遍历的每个的表空间,执行以下步骤:
- 查询
INFORMATION_SCHEMA.INNODB_TABLES以查找属于表空间ID的哪些表,并在底层表或共享表空间中获取MDL锁定。 - 复制表空间的
.ibd文件。
备份过程可能会遇到由批量加载操作生成的redo log事件,该事件通知备份工具从redo log中省略了数据文件更改。此事件是MLOG_INDEX_LOAD。如果重做跟随线程找到了此事件,备份将继续进行,并假定备份是安全的,因为MDL会保护已复制的表空间,并且MLOG_INDEX_LOAD事件是针对尚未复制的表空间的。
这些假设可能不正确,可能导致备份不一致。
--lock-ddl-per-table重新设计
在Percona XtraBackup 8.0.22-15.0版本中实现,--lock-ddl-per-table已经重新设计以最小化不一致的备份。
以下过程重新排序了步骤:
- 备份开始时获得的MDL锁
- 扫描redo log。如果在备份开始前发生了
CREATE INDEX语句,可能会记录MLOG_INDEX_LOAD事件。此时,备份过程是安全的,可以解析和接受此事件。 - 在第一次扫描完成后,启动后续的redo log跟随线程。如果找到
MLOG_INDEX_LOAD事件,该线程将停止备份过程。 - 收集要复制的表空间列表
- 复制
.ibd文件。
其他改进, 以下改进已添加:
- 如果
.ibd文件属于临时表,SELECT 查询将被跳过。 - 对于全文索引,将在基本表上获取 MDL。
- 获取MDL的
SELECT查询不会检索任何数据。
在Percona Server for MySQL 8.0版本中,
--lock-ddl-per-table变量已被弃用。请使用--lock-ddl代替这个变量。
8.智能内存估算
智能内存估算是技术预览功能。在将智能内存估算用于生产环境之前,我们建议你在你的环境中测试从物理备份中还原生产,并且使用备用备份方法以确保冗余性。
Percona XtraBackup 8.0.30-23增加了对智能内存估算功能的支持。通过此功能,Percona XtraBackup在备份阶段复制redo log条目期间计算准备阶段所需的内存。Percona XtraBackup还考虑从磁盘获取的InnoDB页面的数量。
Percona XtraBackup执行备份过程分为两步:
- 创建备份: 创建备份时,Percona XtraBackup复制你的InnoDB数据文件。在复制文件时,Percona XtraBackup运行一个后台进程,监视InnoDB redo日志,也称为事务日志,并从中复制更改。
- 准备备份(Prepare): 在准备阶段,Percona XtraBackup使用复制的事务日志文件对复制的数据文件执行崩溃恢复。Percona XtraBackup将所有的redo log条目读入内存,按空间ID和页面ID对其进行分类,将相关页面读入内存,并检查页面和重做日志记录上的日志序列号(LSN)。如果重做日志LSN比页面LSN更新,则Percona XtraBackup将应用重做日志更改到页面上。
为了准备备份,Percona XtraBackup使用InnoDB缓冲池内存。Percona XtraBackup保留内存以将256个页面加载到缓冲池中。其余的内存用于对重做日志条目进行散列/分类。
可用的内存由--use-memory选项控制。如果缓冲池上的可用内存不足,工作将在多个批次中执行。在处理完批次后,内存被释放,为下一个批次释放空间。此过程会极大地影响性能,因为InnoDB页面保存来自多个行的数据。如果页面的更改在不同的批次中发生,那么该页面将被多次获取和逐出。
智能内存估算的工作原理
在准备阶段,Percona XtraBackup会检查服务器的可用空闲内存,并使用内存,直到达到--use-free-memory-pct选项中指定的限制,以运行--prepare操作。由于向后兼容性的原因,--use-free-memory-pct选项的默认值为0(零),这将该选项定义为禁用状态。例如,如果你设置--use-free-memory-pct=50,则会使用可用空闲内存的50%来准备备份。
从Percona XtraBackup 8.0.32-26开始,你可以使用--estimate-memory选项在备份阶段启用或禁用内存估算功能。默认值为OFF。使用--estimate-memory=ON来启用内存估算:
xtrabackup --backup --estimate-memory=ON --target-dir=/data/backups/在准备阶段,通过指定用于准备备份的可用空闲内存的百分比,启用--use-free-memory-pct选项。--use-free-memory-pct值必须大于0。
例如:
xtrabackup --prepare --use-free-memory-pct=50 --target-dir=/data/backups/9.处理二进制日志
xtrabackup二进制文件与log_status表进行了集成。这种集成使xtrabackup能够打印出备份的对应二进制日志位置,这样你可以使用此二进制日志位置来创建一个新的复制副本(replica从库)或执行时间点恢复。
查找二进制日志位置
在备份完成后,你可以找到与备份对应的二进制日志位置。如果你的备份来自启用了二进制日志记录的服务器,xtrabackup会在目标目录中创建一个名为xtrabackup_binlog_info的文件。此文件包含备份时的二进制日志文件名和位置的确切点。
210715 14:14:59 Backup created in directory '/backup/'
MySQL binlog position: filename 'binlog.000002', position '156'
. . .
210715 14:15:00 completed OK!从Percona XtraBackup 8.0.26-18.0版本开始,xtrabackup不再创建xtrabackup_binlog_pos_innodb文件。这个变化是因为MySQL和Percona Server不再在ibdata的全局事务系统部分更新二进制日志信息。无论使用的存储引擎如何,你都应该依赖于xtrabackup_binlog_info。
时间点恢复
要从xtrabackup备份执行时间点恢复,你应该先准备和恢复备份,然后从xtrabackup_binlog_info文件中显示的位置重放二进制日志。
设置新的复制副本
要设置新的复制副本,你应该准备备份,并将其恢复到新复制副本的数据目录中。如果你使用的是8.0.22或更早版本,在CHANGE MASTER TO命令中,使用xtrabackup_binlog_info文件中显示的二进制日志文件名和位置来启动复制。
如果你使用的是8.0.23或更高版本,请使用CHANGE_REPLICATION_SOURCE_TO和适当的选项。CHANGE_MASTER_TO已被弃用。