Tempo介绍
Grafana Tempo是一个开源的、易于使用的且高吞容量的分布式追踪后端。Tempo具有成本效益高的特点,只需要一个对象存储来运行。Tempo可以和Grafana、Mimir、Prometheus和Loki 深度集成。可以使用Tempo与包括Jaeger、Zipkin或OpenTelemetry在内的开源追踪协议一起使用。
Tempo与许多现有的开源工具集成良好:
- Grafana默认提供了对Tempo的本地支持,使用内置的Tempo数据源。
- Grafana Loki具有强大的查询语言LogQL v2,可以让你查询过滤关心的请求,并使用Grafana中的 Derived fields功能跳转到追踪信息。
- Prometheus exemplars例可以让你通过点击记录的exemplars跳转到Tempo的追踪信息。你可以在博文《Intro to exemplars, which enable Grafana Tempo’s distributed tracing at massive scale》中了解更多关于这种集成的信息。
Tempo从高基数的trace-id字段构建索引。由于Tempo使用对象存储作为后端,因此Tempo可以同时查询多个块(blocks),因此查询具有高度并行性。
Tempo的架构
Tempo由以下组件组成:
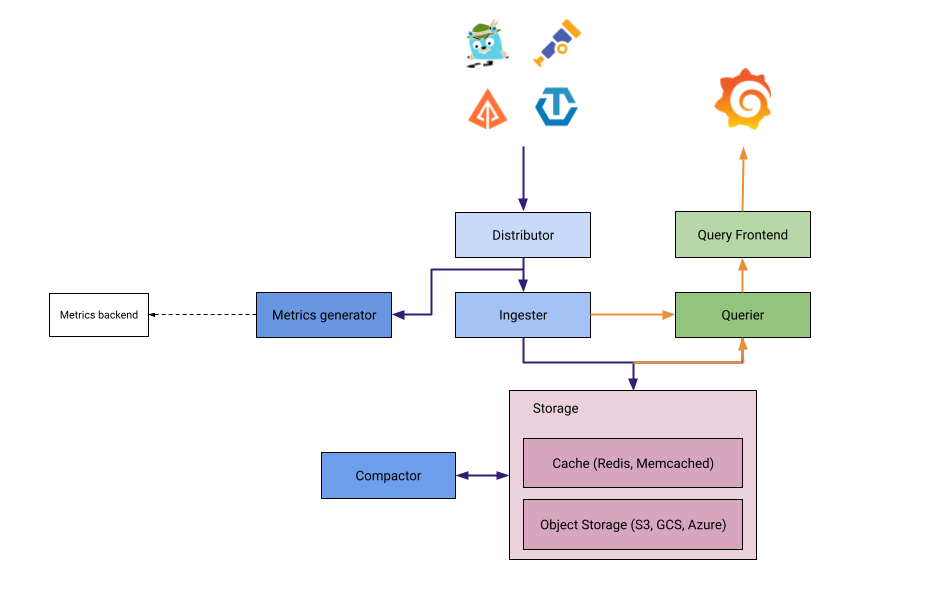
Distributor(分发器): distributor接受多种格式的spans数据,包括Jaeger、OpenTelemetry和 Zipkin。它通过哈希 traceID 并使用分布式一致性哈希环将spans路由到ingesters。distributor使用了OpenTelemetry Collector的接收器层。为了获得最佳性能,建议提取OTel Proto格式的spans。因此,Grafana Agent使用otlp exporter/receiver将spans发送到Tempo。
Ingester: ingester将跟踪数据批处理为块(blocks),创建布隆过滤器和索引,然后将其全部刷新到后端存储。后端存储中的块按照以下布局生成。
<bucketname> / <tenantID> / <blockID> / <meta.json> / <index> / <data> / <bloom_0> / <bloom_1> ... / <bloom_n>Query Frontend: 查询前端负责对传入的查询请求进行分片,以便进行搜索。跟踪数据通过简单的HTTP端点公开:
GET /api/traces/<traceID>在内部,查询前端将块ID空间分割为可配置数量的分片,并将这些请求排入队列。查询器(Queriers)通过流式 gRPC连接与查询前端连接,以处理这些分片查询。Querier: 查询器(Querier)负责在Ingester或后端存储中查找所请求的traceID。根据参数的不同,它将同时查询ingesters,并从后端存储中提取布隆过滤器和索引来搜索对象存储中的块(blocks)。查询器在以下HTTP端点上公开接口:
GET /querier/api/traces/<traceID>,但不建议直接使用该接口。查询应该发送到查询前端(Query Frontend)。Compactor: 压缩器(Compactors)通过流式传输将块(blocks)从后端存储中进行压缩,以减少总块数。
Metrics generator: 指标生成器是一个可选的组件,从提取的跟踪数据中产生指标,并将其写入指标存储。