1. 基于OpenTelemetry的可观测性方案
最近将一个项目的可观测性方案从Logs(ElasticSearch,Fuentbit,Kibana), Traces(Jaeger+OpenTracing)迁移到了OpenTelemetry。此项目由多个微服务组成,部署在一个Kubernetes集群中。 OpenTelemetry Collector由OpenTelemetry K8S Operator管理,并以DaemonSet的形式部署在Kubernetes集群的各个节点上。即每个K8S节点上都有一个OTEL Collector Agent进程负责收集并处理本节点上微服务Pod实例的Logs, Traces, Metrics数据,并将Logs, Traces数据发送到后端的日志存储(Loki或ES)、Traces数据存储(Jaeger或Tempo),同时将Metrics数据暴露给Prometheus。
当前运行的方案如下图所示:
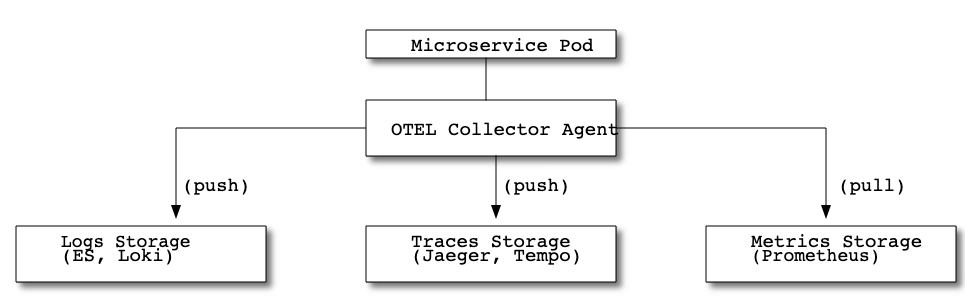
在基于OpenTelemetry的可观测性方案中,每个K8S节点上的OTEL Collector Agent是最关键的组件之一,本问将探索关于OTEL Collector自身监控方面的内容,通过了解关键的监控指标,将OTEL Collector自身可视化,可以在日常对OTEL Collector的配置、分析和处理错误时起到指导性作用。
2. OTEL Collector的监控
OTEL Collector的Prometheus指标在本地通过端口8888和路径/metrics公开。从0.43版本开始可以通过配置文件中的service.telemetry.metrics.address进行配置。
service:
telemetry:
metrics:
address: ":8888"这里提供了一个适用于这些指标的Grafana Dashboard。
2.1 关键监控点
数据丢失
使用otelcol_processor_dropped_spans > 0, otelcol_processor_dropped_metric_points > 0和otelcol_processor_dropped_log_records > 0来检测数据丢失。根据需求设置一个最小的时间窗口,以避免对不被视为故障或不符合所需可靠性水平的少量数据丢失时发送的告警通知。
CPU资源不足
这取决于部署中可用的CPU指标,例如:Kubernetes中的kube_pod_container_resource_limits_cpu_cores。以下将其称为available_cores。这里的想法是设定可用核数的上限,并考虑每个核的最大预期接收(ingestion)速率(称为safe_rate)作为安全系数。当 (actual_rate/available_cores) < safe_rate 时,应触发增加资源/实例(或适时发出告警)。
safe_rate 取决于使用的具体配置。
2.2 次要监控点
队列长度
大多数exporter提供了一个队列/重试机制(queue/retry mechanism),建议将其作为OTEL Collector的重试机制,并在任何生产部署中使用。
otelcol_exporter_queue_capacity指示重试队列的容量(以批次batches计数)。otelcol_exporter_queue_size指示重试队列的当前大小。因此,可以使用这两个指标来检查队列容量是否足够处理您的工作负载。
otelcol_exporter_enqueue_failed_spans、otelcol_exporter_enqueue_failed_metric_points和otelcol_exporter_enqueue_failed_log_records指示无法添加到发送队列中的span/metrics points/log records的数量。这可能是由于队列已满而导致的未解决元素。因此,可能需要降低发送速率或横向扩展收集器。
队列/重试机制还支持日志记录进行监控。检查日志中是否存在诸如"Dropping data because sending_queue is full"的消息。
接收失败
otelcol_receiver_refused_spans、otelcol_receiver_refused_metric_points和otelcol_receiver_refused_log_records的持续速率表示返回给客户端的错误过多。根据部署和客户端的弹性,这可能表示客户端存在数据丢失的情况。
otelcol_exporter_send_failed_spans、otelcol_exporter_send_failed_metric_points和otelcol_exporter_send_failed_log_records的持续速率表示收集器无法按预期导出数据。这并不意味着数据丢失,因为可能会进行重试,但是高失败率可能表示网络或接收数据的后端存在问题。
2.3 数据流
数据进入: otelcol_receiver_accepted_spans、otelcol_receiver_accepted_metric_points和otelcol_receiver_accepted_log_records指标提供有关Collector接收的数据的信息。
数据流出: otecol_exporter_sent_spans、otelcol_exporter_sent_metric_points和otelcol_exporter_sent_log_records指标提供有关Collector导出的数据的信息。