上一节,使用Pulsar官方的Helm Chart在Kubernetes集群中规划并部署了生产可用的Pulsar集群。
在上一节,我们还留了一个小尾巴,在部署Pulsar集群时,禁用了监控相关的组件(promethues, grafana等)。 在以Kubernetes为基础的云原生基础架构中,肯定已经单独部署了以Prometheus为核心的各个监控组件,因此我们希望使用平台统一的Prometheus实现对Pulsar集群的监控。
本节将介绍如何将使用helm chart部署的Pulsar集群接入到已经存在的Prometheus监控系统中。
暴露监控指标给Prometheus
Pulsar作为云原生的消息平台,不仅在架构上可以重复利用分布式、可弹性伸缩的云端资源,还原生支持以Prometheus为核心的云原生监控架构。
Pulsar的各个组件内部都原生集成了Prometheus Exporter的功能。使用Helm Chart部署时,已经为我们在各个组件的manifest设置好了用于Prometheus抓取监控指标的annotation。 例如,Pulsar Proxy的StatefulSet的mainifest中:
spec:
......
template:
metadata:
...
annotations:
prometheus.io/port: '80'
prometheus.io/scrape: 'true'也就是说,Pulsar的Proxy, Broker, Bookie, Zookeeper等组件默认就会向Kubernetes集群中的Prometheus暴露监控指标。
需要注意的是,Proxy组件如果开启了认证的话,处于安全考虑,Proxy组件的Prometheus Exporter端点也就自动开启了认证,为了确保Prometheus可以抓取到Proxy的监控指标, 这里关闭了Proxy组件监控端点的认证,以下是在pulsar helm chart values文件中关闭这个认证的配置。
...
proxy:
...
configData:
PULSAR_PREFIX_authenticateMetricsEndpoint: "false"
...啰嗦了半天,一句话概况就是,如果你是使用pulsar helm chart部署的,pulsar各个组件的各个监控指标会自动暴露给K8S中的Prometheus。
可以直接在K8S集群中查看,下图的PromQL分组查询了Pulsar集群各个组件总的监控指标数:
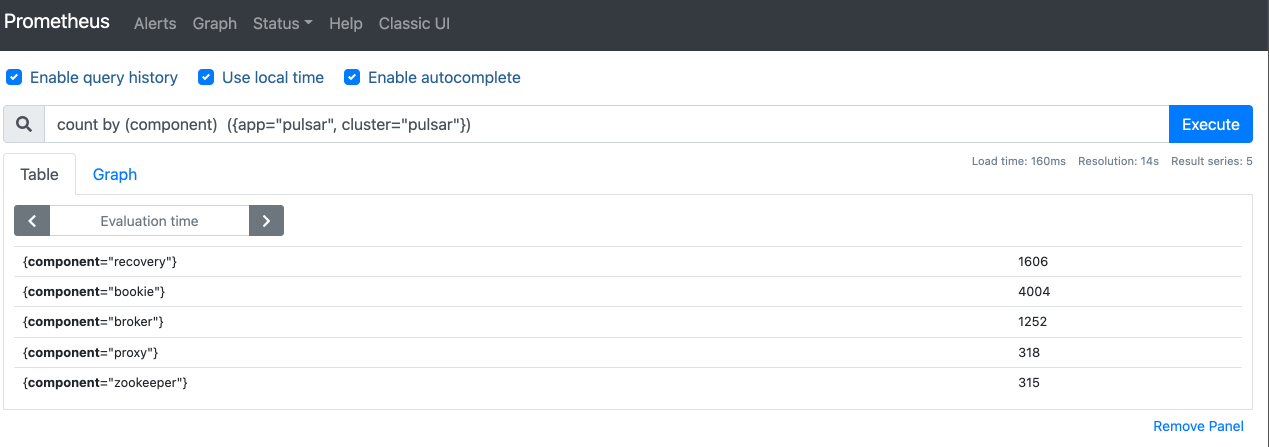
配置Grafana监控面板
使用Prometheus中关于Pulsar的监控数据,可以在Grafana中创建监控面板。
https://github.com/streamnative/apache-pulsar-grafana-dashboard这个项目为Pulsar的各个组件提供了
Grafana 监控面板模板。Pulsar Helm Chart中使用的是streamnative/apache-pulsar-grafana-dashboard-k8s容器镜像,从该镜像中启动的容器中包含一个grafana实例并集成上这些监控面板模板。
因为我们这里的目标是不使用pulsar helm chart中内置的Prometheus和Grafana,而是使用外部Kubernetes集群中统一的Prometheus和Grafana。
为了得到这些监控面板的模板,可以先修改Pulsar的部署,将pulsar helm chart中的Grafana启用,导出Pulsar各个组件的监控模板后,再将pulsar helm chart中的Grafana禁用。
将前面导出的监控面板模板导入到外部的Grafana中。
为了使各个监控面板正确的显示监控指标,需要正确配置Prometheus以确保其可以正确的收集Pulsar的监控指标:
- 在Grafana中创建监控面板模板中的Prometheus数据源,要求名称一致
- 通过修改Prometheus的配置确保Promethues对每个组件的job名称与监控面板模板中的名称一致
- proxy组件的job为proxy
- broker组件的job名称为broker
- bookies组件的job名称为bookie
- zookeeper组件的job名称为zookeeper
- …
上面两项配置,根据具体的Prometheus和Grafana部署环境决定,例如下面是通过Prometheus监控Pulsar各组件Pod时,通过relabel_configs将job名称替换为各个组件的名称。
- job_name: 'kubernetes-pods'
kubernetes_sd_configs:
- role: pod
relabel_configs:
...
- source_labels: [__meta_kubernetes_pod_label_component]
action: replace
target_label: job
...下图,为配置完成的多个监控面板中的一个:
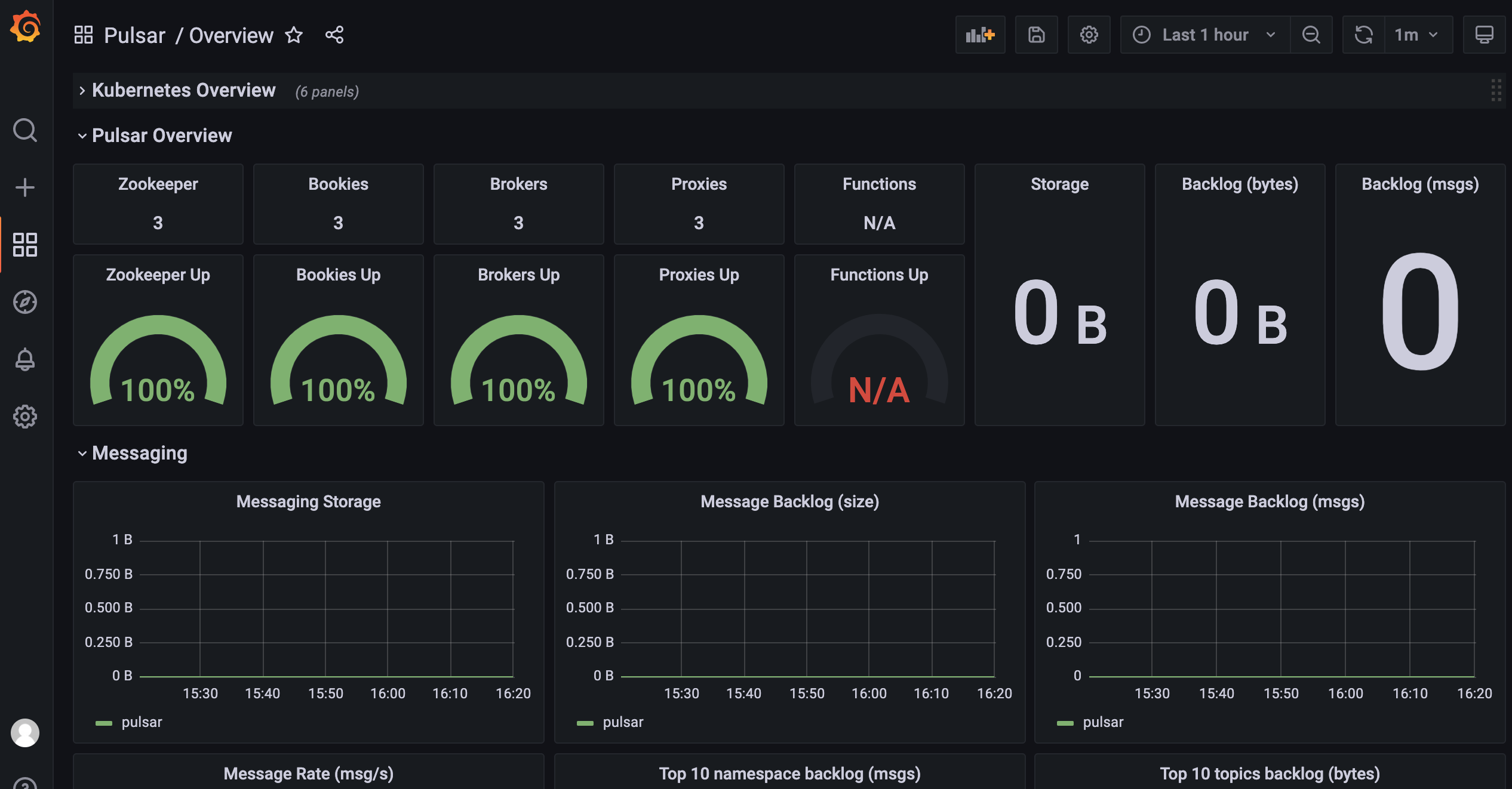
配置监控告警规则
可以为Pulsar集群配置Prometheus的监控告警规则,这里的监控告警规则参考了https://github.com/streamnative/examples/blob/master/platform/values_cluster.yaml中的例子。
groups:
- name: zookeeper
rules:
- alert: HighWatchers
expr: zookeeper_server_watches_count{job="zookeeper"} > 1000000
for: 30s
labels:
status: warning
annotations:
summary: "Watchers of Zookeeper server is over than 1000k."
description: "Watchers of Zookeeper server {{ $labels.instance }} is over than 1000k, current value is {{ $value }}."
- alert: HighEphemerals
expr: zookeeper_server_ephemerals_count{job="zookeeper"} > 10000
for: 30s
labels:
status: warning
annotations:
summary: "Ephemeral nodes of Zookeeper server is over than 10k."
description: "Ephemeral nodes of Zookeeper server {{ $labels.instance }} is over than 10k, current value is {{ $value }}."
- alert: HighConnections
expr: zookeeper_server_connections{job="zookeeper"} > 10000
for: 30s
labels:
status: warning
annotations:
summary: "Connections of Zookeeper server is over than 10k."
description: "Connections of Zookeeper server {{ $labels.instance }} is over than 10k, current value is {{ $value }}."
- alert: HighDataSize
expr: zookeeper_server_data_size_bytes{job="zookeeper"} > 107374182400
for: 30s
labels:
status: warning
annotations:
summary: "Data size of Zookeeper server is over than 100TB."
description: "Data size of Zookeeper server {{ $labels.instance }} is over than 100TB, current value is {{ $value }}."
- alert: HighRequestThroughput
expr: sum(irate(zookeeper_server_requests{job="zookeeper"}[30s])) by (type) > 1000
for: 30s
labels:
status: warning
annotations:
summary: "Request throughput on Zookeeper server is over than 1000 in 30 seconds."
description: "Request throughput of {{ $labels.type}} on Zookeeper server {{ $labels.instance }} is over than 1k, current value is {{ $value }}."
- alert: HighRequestLatency
expr: zookeeper_server_requests_latency_ms{job="zookeeper", quantile="0.99"} > 100
for: 30s
labels:
status: warning
annotations:
summary: "Request latency on Zookeeper server is over than 100ms."
description: "Request latency {{ $labels.type }} in p99 on Zookeeper server {{ $labels.instance }} is over than 100ms, current value is {{ $value }} ms."
- name: bookie
rules:
- alert: HighEntryAddLatency
expr: bookkeeper_server_ADD_ENTRY_REQUEST{job="bookie", quantile="0.99", success="true"} > 100
for: 30s
labels:
status: warning
annotations:
summary: "Entry add latency is over than 100ms"
description: "Entry add latency on bookie {{ $labels.instance }} is over than 100ms, current value is {{ $value }}."
- alert: HighEntryReadLatency
expr: bookkeeper_server_READ_ENTRY_REQUEST{job="bookie", quantile="0.99", success="true"} > 1000
for: 30s
labels:
status: warning
annotations:
summary: "Entry read latency is over than 1s"
description: "Entry read latency on bookie {{ $labels.instance }} is over than 1s, current value is {{ $value }}."
- name: broker
rules:
- alert: StorageWriteLatencyOverflow
expr: pulsar_storage_write_latency{job="broker"} > 1000
for: 30s
labels:
status: danger
annotations:
summary: "Topic write data to storage latency overflow is more than 1000."
description: "Topic {{ $labels.topic }} is more than 1000 messages write to storage latency overflow , current value is {{ $value }}."
- alert: TooManyTopics
expr: sum(pulsar_topics_count{job="broker"}) by (cluster) > 1000000
for: 30s
labels:
status: warning
annotations:
summary: "Topic count are over than 1000000."
description: "Topic count in cluster {{ $labels.cluster }} is more than 1000000 , current value is {{ $value }}."
- alert: TooManyProducersOnTopic
expr: pulsar_producers_count > 10000
for: 30s
labels:
status: warning
annotations:
summary: "Producers on topic are more than 10000."
description: "Producers on topic {{ $labels.topic }} is more than 10000 , current value is {{ $value }}."
- alert: TooManySubscriptionsOnTopic
expr: pulsar_subscriptions_count > 100
for: 30s
labels:
status: warning
annotations:
summary: "Subscriptions on topic are more than 100."
description: "Subscriptions on topic {{ $labels.topic }} is more than 100 , current value is {{ $value }}."
- alert: TooManyConsumersOnTopic
expr: pulsar_consumers_count > 10000
for: 30s
labels:
status: warning
annotations:
summary: "Consumers on topic are more than 10000."
description: "Consumers on topic {{ $labels.topic }} is more than 10000 , current value is {{ $value }}."
- alert: TooManyBacklogsOnTopic
expr: pulsar_msg_backlog > 50000
for: 30s
labels:
status: warning
annotations:
summary: "Backlogs of topic are more than 50000."
description: "Backlogs of topic {{ $labels.topic }} is more than 50000 , current value is {{ $value }}."
- alert: TooManyGeoBacklogsOnTopic
expr: pulsar_replication_backlog > 50000
for: 30s
labels:
status: warning
annotations:
summary: "Geo backlogs of topic are more than 50000."
description: "Geo backlogs of topic {{ $labels.topic }} is more than 50000, current value is {{ $value }}."