Apache Pulsar简介
Apache Pulsar是一个支持多租户的、高性能的、分布式的Pub-Sub消息系统,最初由雅虎开发,现在是Apache软件基金会的顶级项目。 Pulsar提供非常低的消息发布和端到端的延迟、保障消息可靠传递零丢失,同时提供了一个用于流数据处理的无服务器轻量级计算框架。
Pulsar为处理大数据集提供了三个核心功能:
- 实时消息传递: Pulsar支持在不同的地理位置生产和消费消息,Pulsar的跨机房复制可以实现这一操作。Pulsar允许部署在不同地域的应用和系统通过消息交换来进行异步通信,支持多种编程语言和二进制消息传输协议。
- 实时计算: Pulsar提供在允许在其自身内部对消息执行用户定义计算的能力,而不需要外部计算系统执行基本的数据转换操作(对数据的填充、过滤、聚合等)
- 可扩展的存储: Pulsar在存储上使用了分层存储(Tiered Storage),这使得消息数据可以保留用户需要保留的时间。Pulsar对其保留和可提供访问的消息的数据量没有物理限制。
Pulsar采用基于段的消息存储
一般的消息系统在逻辑上都可分为服务层和存储层两层:
- 服务层: 直接与消息的生产者(Producer)和消费者(Consumer)交互,接收传入的消息并将消息路由到一个或多个目的地。服务层通过支持的消息协议进行通讯,例如AMQP。服务层在消息协议转换上依赖CPU,在通信上依赖网络带宽。
- 存储层: 负责消息的存储。存储层与服务层交互提供服务层请求的消息,存储层保持消息的正确顺序。存储层严重依赖硬盘来存储消息。
分布式消息系统与传统单点消息系统在架构上的主要差别在于存储层的设计方式。在分布式消息传递系统中,数据分布在集群中的多台机器上,允许在单个主题中保留超过单个机器存储容量的消息。分布式消息系统存储层的关键架构抽象是“write-ahead-log”,它将存储的消息看成是单个仅追加的数据结构。 对于分布式消息系统,当新消息发布到主题(Topic)时,从逻辑的角度来看,消息将被追加到日志的末尾;从物理的角度来看,消息可能写入集群中的任何服务器。
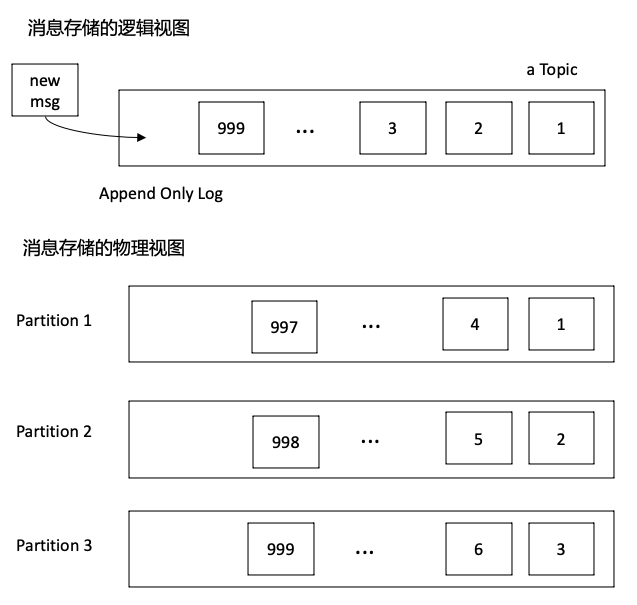
分布式消息系统的另一个好处是将负载分散到多台机器上,可以提高消息的生产和消费的吞吐量,每台服务器都有自己硬盘和写入路径,将提供更好的写入速率。
在分布式消息系统集群中分布消息数据时,有两种不同的方法: 基于分区(Partion-based)和基于段(Segment-based)。
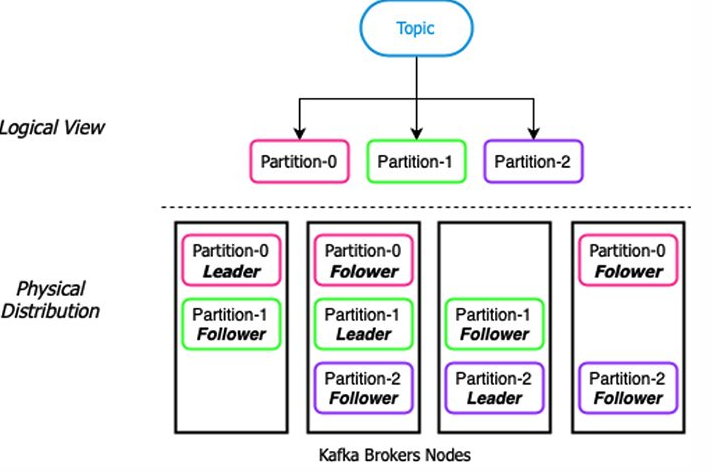
在基于分区的消息存储结构中,Topic被划分为固定数量的分区,发布到Topic中的数据均匀的分布在分区中,同时为了确保数据冗余,每个分区会被复制到不同的节点。如下例图所示,每个分区接收到的发布到Topic的消息总数的三分之一。Topic中消息的总存储量为Topic的分区数乘以每个分区的大小,如果达到这个限制,需要向集群添加更多的节点同时增加Topic的分区数量才能继续向分区中添加数据,增加分区的数量还需要执行重新平衡,这是一个十分复杂和耗时的过程。在基于分区的消息存储结构的分布式消息系统中,一般在创建Topic的时候需要预先确定分区数量,但这样做有一些缺点,因为单个分区只会存储在集群中单个集群节点上,因此单个分区的大小就受限于该节点上的硬盘空间大小,由于Topic中的数据均匀分布在所有分区中,所以如果集群节点的硬盘容量不一样的话,那么Topic的每个分区的大小将限制为最小硬盘容量的节点。当Topic达到容量限制后,唯一能做的就是增加Topic的分区数量,但这个扩容的过程包括重新平衡整个Topic,Topic中的数据将被重新分布到该Topic的所有分区中,平衡数据的过程十分消耗网络带宽和磁盘I/O。 Kafka采用的是基于分区的消息存储架构。
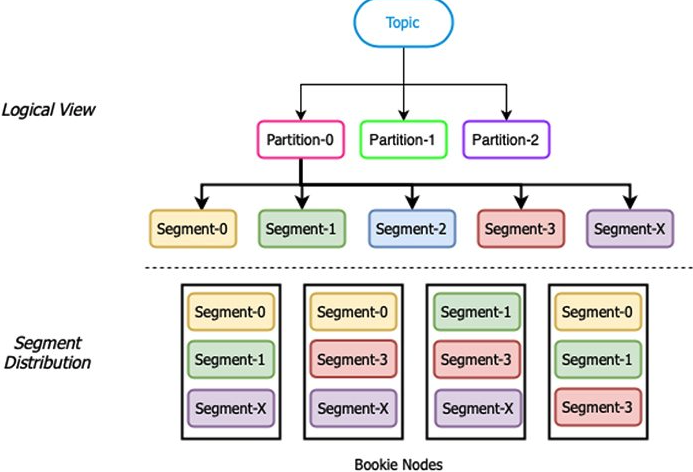
Pulsar采用的是基于段的消息存储结构。Pulsar依赖Apache BookKeeper项目来实现消息的持久存储,BookKeeper的逻辑存储模型是基于无限流记录作为顺序日志存储的概念。从下图可以看出,在BookKeeper中,每个日志被分解成更小的数据块,称为段(Segament),这些数据块又由多个日志条目组成。然后,为了实现冗余和扩展,这些段会在存储层中被称为bookies的多个节点上写入。可以将段放在集群节点具有足够硬盘容量的任何位置,当没有足够的空间用于存储新的段时,可以方便地添加节点并立即存储数据。基于段的存储架构的优点在于可以实现真正的水平伸缩,段可以被无限创建并存储在任何位置。