1.为什么要内存对齐?
先来看一下字长的概念。字长是CPU的主要技术指标之一,指的是CPU一次能并行处理的二进制位数,通常CPU的字长为4字节(32位)、8字节(64位)。 CPU在访问内存时,并不是逐个字节访问的,而是以字长为单位访问。这么做的目的是为了减少CPU访问内存的次数,例如对于64位CPU,一次读取16字节数据只需要读取2次。
例1:
package main
import (
"fmt"
)
type foo struct {
f1 int8
f2 int64
}
func main() {
var s foo
fmt.Println(s)
}例1中的代码定义了一个简单的结构体foo,这个结构体包含两个字段int8类型的f1占用1个字节,int64乐行的f2占8个字节。
在main函数中声明结构体foo的变量s。变量s在内存中的布局有两种选择,一种是非内存对齐,另一种是内存对齐。下面以示意图的形式画一下这种情况下s变量的内存布局,其中内存对齐的方式选择以8字节的形式对齐。
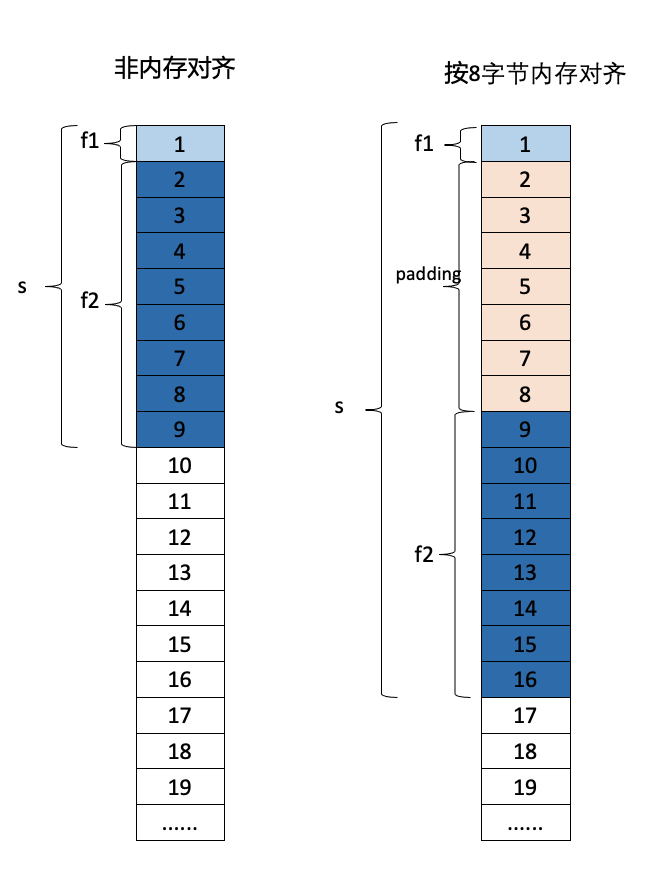
上图中左边是内存不对齐的示意图,变量s中的f1和f2字段根据各自占有字节大小紧凑布局,在这种情况下s变量大小为9个字节。上图中右边是内存以8字节形式对齐,变量s中的f1占了1个字节,紧跟后边填充了7字节的padding,使后边的f2按照8字节对齐,在这种情况下s变量的带下为16字节。
假设字长为8字节的CPU:
- 如果变量s的内存布局不对齐的话,从内存读取s变量中的f1字段,只需读取一次,读取f2字段,需要读取两次,因为f2字段的布局跨了两个字长,需要分别读取这两个字。
- 如果变量s的内存布局采用了8字节的形式对齐的话,从内存读取s变量中的f1字段,只需读取一次,读取f2字段,也只需读取一次。
从这个例子可以看出,内存对齐减少了内存的读取次数,性能将更好,同时由于内存对齐保障了读取f2是单次读取,使得更易实现变量读取的原子性。 但内存对齐后,f1和f2之间填充的padding中并没有存储有效数据,所以占用的内存会更大。因此,内存对齐实际上是以空间换时间。
2.内存对齐规则
前面学习了内存对齐是以空间换时间,避免CPU以字长为单位加载不对齐的内存时的性能问题。 Go语言的编译器也采用了内存对齐的形式,在学习结构体的内存对齐规则之前,先来看几个概念。
2.1 类型的长度(Size)
类型的长度(Size): 每个类型都有其长度size。下面看一下一些Go中常见类型的长度。
int8的长度是1字节,float32长度是4字节,切片slice的长度在64位机器上是24字节,因为slice的底层是一个struct:
// runtime/slice.go
type slice struct {
array unsafe.Pointer // 8 bytes
len int // 8 bytes
cap int // 8 bytes
}这个struct在64位机器上,array指针, len, cap都是8字节,所以slice的size是24字节。注意切片的长度不是它所引用的底层数组的长度。
string的长度在64位机器上是16字节,因为string的底层是一个struct:
// runtime/string.go
type stringStruct struct {
str unsafe.Pointer
len int
}这个struct在64位机器上,str指针, len都是8字节,所以string的size是16字节。
在Go语言中可以使用unsafe.Sizeof函数来获取某个类型的变量的长度,例如,例2:
func main() {
fmt.Println(unsafe.Sizeof(int64(1))) // 8
fmt.Println(unsafe.Sizeof(float32(32))) // 4
fmt.Println(unsafe.Sizeof("")) // 16
fmt.Println(unsafe.Sizeof([]int{})) // 24
fmt.Println(unsafe.Sizeof([2]int64{})) // 16
}unsafe.Sizeof文档中是这样描述这个函数的: func Sizeof(v ArbitraryType) uintptr,Sizeof返回类型v本身数据所占用的字节数。返回值是“顶层”的数据占有的字节数。例如,若v是一个切片,它会返回该切片描述符的大小,而非该切片底层引用的内存的大小。
2.2 类型的对齐系数(Align)
类型的对齐系数: 每个类型都有一个对齐系数,对齐系数是与内存对齐规则有关的值:
- Go原始类型的对齐系数与类型长度相等。
- Go结构体类型的对齐系数是最长字段的对齐系数和系统对齐系数两者中的最小的那个。 (系统对齐系数,32位系统默认为4字节, 64位系统默认为8字节)
下面看一些常见类型的对齐系数:
int64的长度是8字节,对齐系数也是8字节float32的长度是4字节,对齐系数也是4字节string的长度是16字节,因为其底层是一个拥有字段str unsafe.Pointer和len int的struct,对齐系数取最长字段的对齐系数和系统对齐系数的最小值,在64位系统上,都是8字节,所以string的对齐系数是8- 切片slice的长度是24字节,,因为其底层是一个拥有字段
array unsafe.Pointer,len int和cap int的struct,对齐系数取最长字段的对齐系数和系统对齐系数的最小值,在64位系统上,都是8字节,,所以切片的对齐系数是8 - …
在Go语言中可以使用unsafe.Alignof函数来获取某个类型的变量对齐系数,例如,例3:
func main() {
fmt.Println(unsafe.Sizeof(int64(1))) // 8
fmt.Println(unsafe.Sizeof(float32(32))) // 4
fmt.Println(unsafe.Sizeof("")) // 16
fmt.Println(unsafe.Sizeof([]int{})) // 24
fmt.Println(unsafe.Sizeof([2]int64{})) // 16
fmt.Println("###############")
fmt.Println(unsafe.Alignof(int64(1))) // 8
fmt.Println(unsafe.Alignof(float32(32))) // 4
fmt.Println(unsafe.Alignof("")) // 8
fmt.Println(unsafe.Alignof([]int{})) // 8
fmt.Println(unsafe.Alignof([2]int64{})) // 8
}2.3 字段偏移量(Offset)
字段偏移量(Offset): 是指结构体变量在内存对齐后,结构体字段在结构体中的偏移量,是字段相对于结构体起始位置偏移的字节数。即这个偏移量是指该字段与结构体起始点(第一个字段)之间的字节数。结构体的第一个字段的Offset是0。
例如在本文开始的例1中的foo struct中字段f1的offset是0,字段f2的offset是8,因为f1后边填充了7字节的padding。
2.4 struct内存对齐规则
有了类型长度Size、对齐系数Align、字段偏移量offset的基础,来看一下在Go中struct的内存对齐规则:
- 首先确定struct的每个字段的长度Size和对齐系数Align
- 其次保证每个字段的Offset与其对齐系数Align"对齐",这里"对齐"的意思是要保证字段Offset是其Align的整数倍,如果不能保证则需要在字段前面添加padding直到能对齐。
- 最后要保证整个结构体的长度Size与结构体自己的对齐系数Align"对齐",即最后确定结构体的长度是结构体Align的整数倍
学习了内存对齐规则,来看下面的例子, 例4(64位操作系统下运行):
type S1 struct { // align=2, size=6
f1 int8 // size=1, align=1, offset=0, padding=1,
f2 int16 // size=2, align=2, offset=2,
f3 int8 // size=1, align=1, offset=4, padding=1
}
type S2 struct { // align=2, size=4
f1 int8 // size=1, align=1, offset=0,
f3 int8 // size=1, align=1, offset=1,
f2 int16 // size=2, align=2, offset=2,
}
func main() {
s1 := S1{}
s2 := S2{}
fmt.Println(unsafe.Sizeof(s1)) // 6
fmt.Println(unsafe.Sizeof(s2)) // 4
}例4中定义了两个结构体S1和S2,这两个结构体的区别只是字段顺序不一样。当我们输出变量s1和s2的Size时,S1的长度是6字节,S2的长度是是4字节。
下面从内存对齐规则,来分析一下变量s1和s2内存对齐布局。
变量s1的类型是S1结构体类型:
- 第1步根据内存对齐规则,首先确定S1的每个字段的长度和对齐系数
- 字段f1 size=1, align=1
- 字段f2 size=2, align=2
- 字段f3 size=1, align=1
- 第2步确保每个字段的offset与其对齐系数对齐,即保证每个字段的Offset是其对齐系数Align的整数倍,如果不能保证则在其前面添加padding直到能对齐
- 字段f1 size=1, align=1, offset=0, padding=1
- 字段f2 size=2, align=2, offset=2 (如果其前面不加padding,offset为1,不能对齐,为了对齐offset需要等于2,所以在其前面加了1字节的padding)
- 字段f3 size=1, align=1, offset=4 (f3的前面不需要填充padding就能对齐)
- 第3步要保证整个结构体的长度Size与结构体自己的对齐系数Align"对齐"
- 结构体的最长字段f2对齐系数为2,64位系统对齐系数为8,取2者中较小的那个座位结构体的对齐系数为2
- 根据第2步的结果,当前结构体变量的长度为
f1 size + padding + f2 size + f3 size = 1 + 1 + 2 + 1 = 5,长度5和对齐系数2不能对齐,所以还需要在f3的后边添加1字节padding才能使结构体对齐 - 最后得出结构体S1的变量长度为
f1 size + padding + f2 size + f3 size + padding = 1 + 1 + 2 + 1 + 1= 6
变量s2的类型是S2结构体类型:
- 第1步根据内存对齐规则,首先确定S2的每个字段的长度和对齐系数
- 字段f1 size=1, align=1
- 字段f3 size=1, align=1
- 字段f2 size=2, align=2
- 第2步确保每个字段的offset与其对齐系数对齐
- 字段f1 size=1, align=1, offset=0
- 字段f3 size=1, align=1, offset=1 (f3前面不需要添加padding直接对齐)
- 字段f2 size=2, align=2, offset=2 (f2前面不需要添加padding直接对齐)
- 第3步要保证整个结构体的长度Size与结构体自己的对齐系数Align"对齐"
- 结构体S2对齐系数为2, 前面第2步完成后结构体的长度为4,直接对齐,不需要padding
根据前面的分析结果,绘制出变量s1和s2的内存对齐后的布局示意图如下:
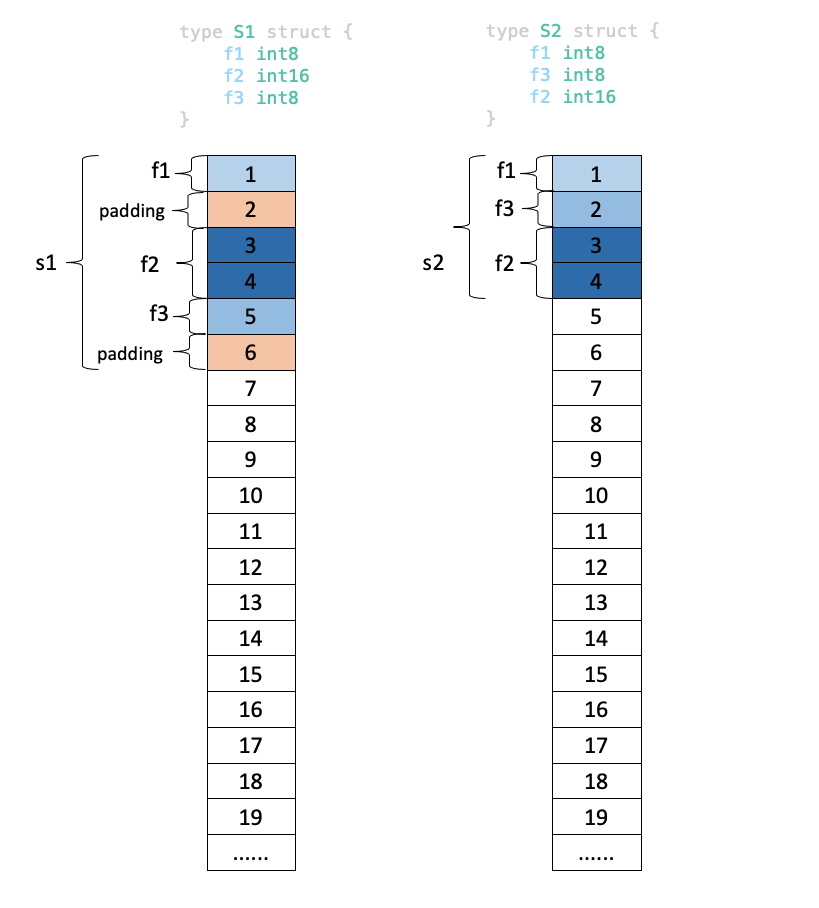
从例4中的代码可以看出,当前Go语言的编译器还不能在进行struct的内存对齐时,针对结构体的字段顺序进行优化。内存对齐会影响struct的内存占用大小,不同的字段顺序的struct内存大小可能不同。 因此,在Go中编写Struct时,合理的字段顺序也许能够优化struct的内存大小。
最后可以用前面学习的go语言struct内存对齐知识分析一下下面这个go程序的输出:
package main
import (
"fmt"
"unsafe"
)
func main() {
var s1 struct {
a string // 16
b bool // 1
c bool // 1, padding=6
}
fmt.Println(unsafe.Sizeof(s1)) // 24
var s2 struct {
a byte // 1, padding=7
b int64 // 8
c string // 16
}
fmt.Println(unsafe.Sizeof(s2)) // 32
var s3 struct {
a byte // 1, padding=7
b int64 // 8
c []int // 24
}
fmt.Println(unsafe.Sizeof(s3)) // 40
var s4 struct {
a byte // 1, padding=7
c []int // 24
b int64 // 8
d string // 16
}
fmt.Println(unsafe.Sizeof(s4)) // 56
}