所有权和生命周期是Rust同其他编程语言的主要区别。本文将先学习Rust的所有权,所有权是Rust的核心功能之一。
不同编程语言开发的程序在运行时采用不同的方式管理内存,一些语言(如Go, Java, Python)具有垃圾回收机制;还有一些语言(C/C++)必须由程序员自己分配和释放内存;Rust则采用了独特的方式:通过所有权系统管理内存,编译器在编译时会根据所有权规则对内存的使用进行检查。在运行时,所有权系统的任何功能都不会减慢程序。
程序的内存布局、栈、堆
对Rust语言来说,变量的值是位于栈(Stack)上,还是位于堆(Heap)上会影响Rust语言的行为,因此在学习所有权之前,我们先了解一下程序进程的内存布局、栈、堆。
在Linux系统中,一个程序进程在内存布局上遵循一定规律,进程的内存空间布局由高地址到低地址大致可分为以下几段:
- 栈(stack): 用户态的栈,栈的大小是固定的,其大小可以使用ulimit -s查看和调整,一般默认为8Mb,栈从高地址向低地址增长(函数调用)
- 堆(heap): 动态分配的内存空间,程序在运行时动态分配和释放,堆内存的分配不是连续的,整体上是从低地址向高地址增长
- bss(未初始化数据区): 未初始化数据区bss, 存放全局的未初始化赋值的变量
- data(初始化数据区): 存放已经初始化的全局变量数据
- text: 存放程序代码
在Linux可执行文件的格式是ELF格式,可以通过分析ELF文件格式以及ELF如何被加载到内存等知识了解Linux下程序进程的布局。这里将程序进程内存布局简化如下图所示:
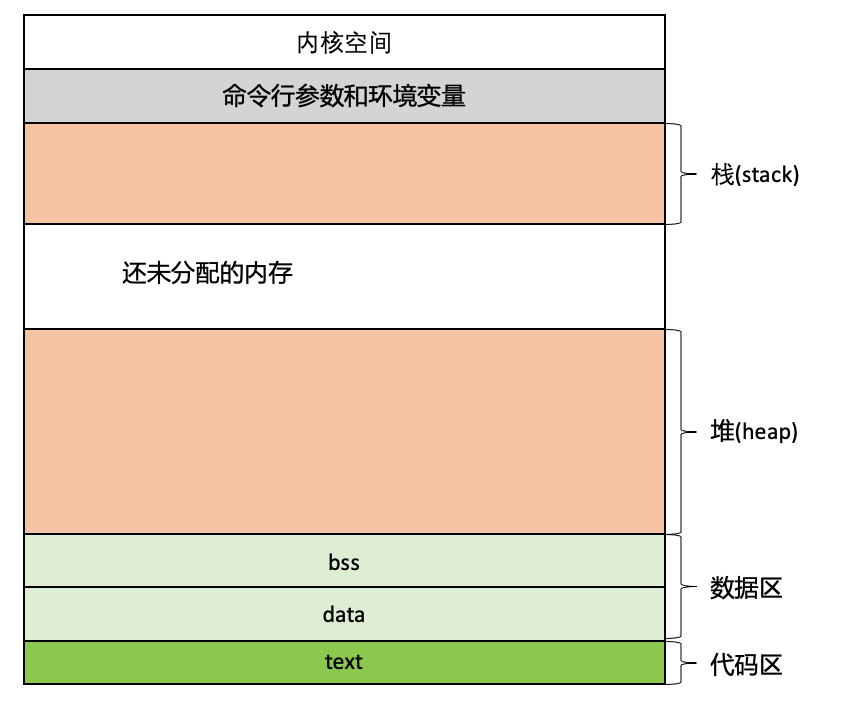
内存地址从高到底依次是:程序启动的命令行参数和环境变量、栈、堆、数据区(bss, data)、代码区。
其中栈和堆都是程序代码在运行时可以使用的内存:
- 栈的分配上是连续的,从高地址向低地址增长,后进先出,入栈增加数据,出栈移出数据
- 堆是动态分配的内存空间,程序在运行时动态分配和释放,因此堆内存的分配是不连续的,但整体趋势上是从低地址向高地址增长。
从栈内存、堆内存在使用特点上,可以得出以下知识点:
- 栈中数据必须占用已知的且固定的内存大小,且在编译时就是确定的
- 编译时占用内存大小未知的数据或者占用内存大小可能在运行时变化的数据,需要存储在堆上
- 数据入栈的速度要比在堆上分配内存的速度快,因为在堆上分配内存需要为存放的数据搜索可用的内存空间
- 访问栈上的数据要比访问堆上的数据速度快,因为堆上的数据需要使用指针来访问,现代处理器在内存中跳转越少就越快
- 调用函数时,传递给函数的值和函数内的局部变量的值会被压入栈中(入栈的值包括指向堆上数据的指针),当函数调用结束时,这些值被移出栈
可以看出程序对内存的管理,主要是指对堆内存的管理,需要跟踪堆上哪些数据正在被使用,最大限度的减少堆上的重复数据,清理堆上不再使用的数据确保内存不会耗尽。
不同编程语言采用不同的内存管理方式,在Rust中是使用所有权系统来管理堆上的数据的。
rust的所有权规则
Rust所有权的存在主要是为了管理堆数据的,所有权系统负责跟踪哪部分代码正在使用堆上的哪些数据,最大限度的减少堆上的重复数据数量,以及清理堆上不再使用的数据确保不会耗尽空间。
为了学习rust的所有权规则,以std::string::String为例,String是一个结构体类型,查看String类型源码,它实际上是一个Vec<u8>的封装:
#[derive(PartialOrd, Eq, Ord)]
#[cfg_attr(not(test), rustc_diagnostic_item = "string_type")]
#[stable(feature = "rust1", since = "1.0.0")]
pub struct String {
vec: Vec<u8>,
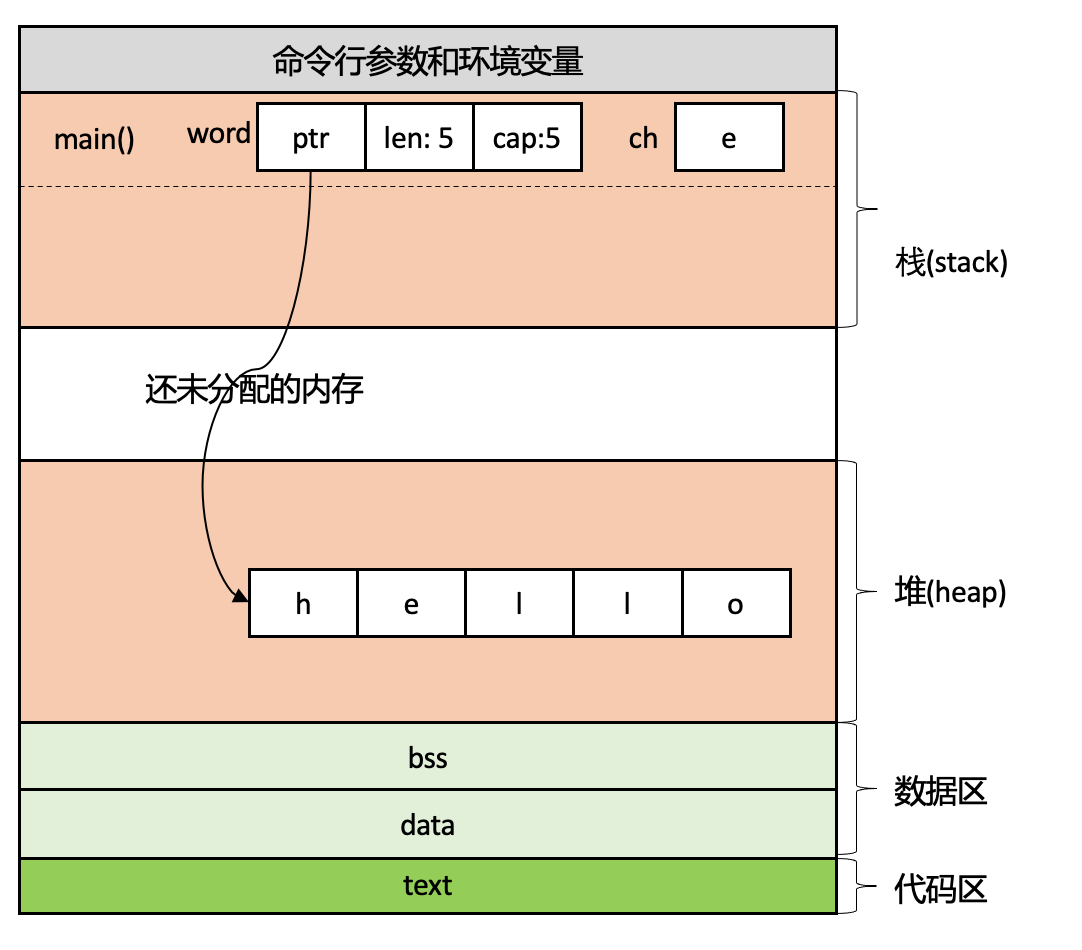
}String内部的vec是一个存放u8类型的动态数组,因此在编译时是无法确定大小的,所以String的数据会被放在堆上,同时在栈上会有一个包含长度和容量的胖指针指向堆上的内存。以下面的代码为例:
fn main() {
let word = String::from("hello");
let ch = 'e';
if let Some(i) = find(word, ch) {
println!("i = {}", i)
}
}
fn find(s: String, c: char) -> Option<usize> {
s.find(c)
}这段代码main函数中声明了变量word和ch,因为word是String类型,将在堆上分配,同时栈上有一个胖指针指向堆上分配的内存,ch值char类型,将在栈上分配。当这段代码的第3行执行完成后,胖指针word和ch的值入栈,胖指针word指向了堆上分配的内存,如下图所示。
代码的第4行调用了find函数,main函数中的局部变量word和ch作为参数传递给了find函数,find函数的参数入栈。此时,如果按照大多数编程语言的处理方式,堆上hello的内存就有word和s两个引用,如下图所示:
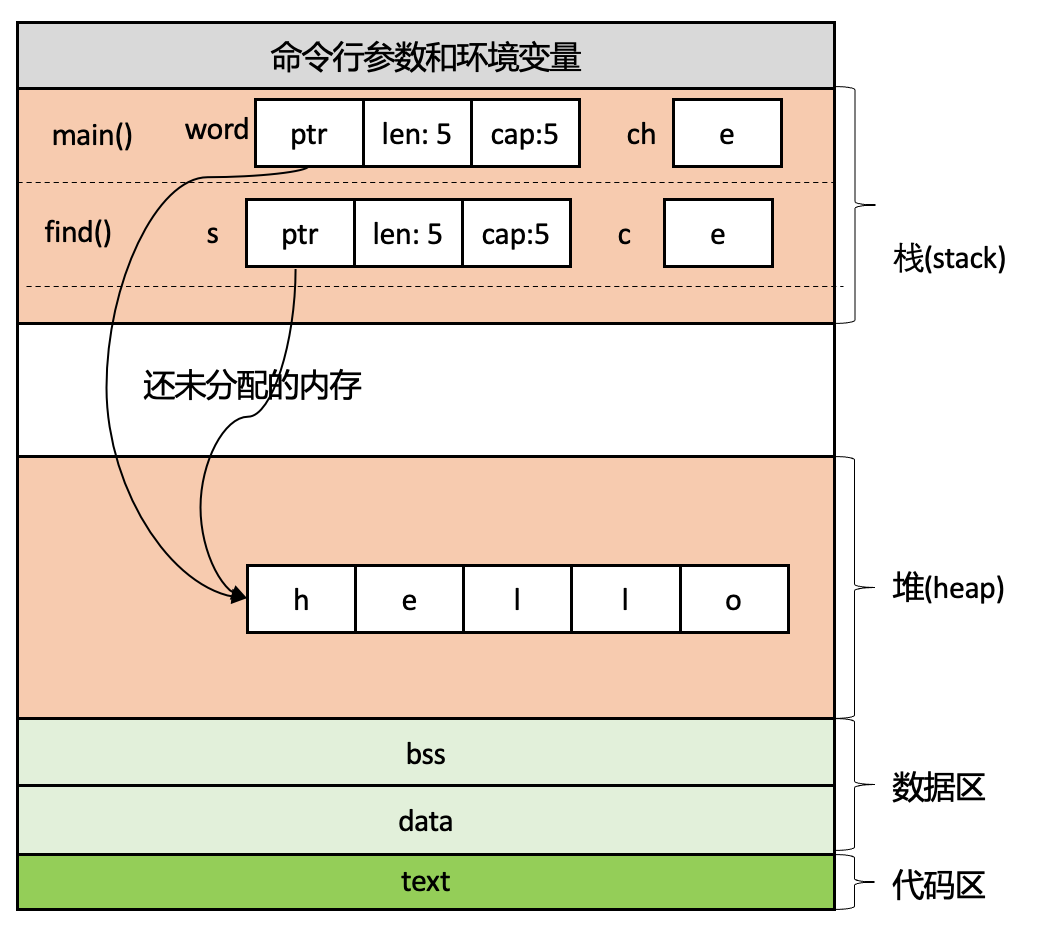
如果按照大多数编程语言允许堆上分配的内存存在多个引用的话,就意味着有多次函数调用和参数传递的话,堆上分配的内存就会多几个引用。 这样的话就很难明确堆内存应该什么时候被释放,同时引用之间也不清楚别的引用对堆内存执行了什么操作,这就给内存管理带来了很大的挑战。 前面已经提到了不同的编程语言采用不同的管理堆内存的方式:
- 一些语言(如Go, Java, Python)具有垃圾回收机制。垃圾回收机制一般是通过定期扫描堆上的数据还有没有被引用,如果没有被引用则可以通过垃圾回收(GC)来为我们自动管理堆内存,但垃圾回收的运行时损耗以及垃圾回收的STW(stop the world)问题对程序性能影响较大。
- 还有一些语言(C/C++)必须由程序员自己分配和释放内存。程序员自己手动分配和释放内存的方式,严重依赖于个人,一个小问题就可能会导致内存安全问题。
Rust语言采用了独特的方式管理内存,通过所有权机制管理内存,编译器在编译时会根据所有权规则对内存的使用进行检查。在运行时,所有权系统的任何功能都不会减慢程序。在Rust中不允许随意的引用堆内存,所有权就是堆上数据的拥有和释放权,在Rust中这个权利是独占的,即单一所有权。
Rust有以下3条所有权规则需要我们牢记:
- Rust中的每一个值都有一个被称为其所有者(owner)的变量。(Each value in Rust has a variable that’s called its owner.)
- 一个值在同一时刻有且只有一个所有者。(There can only be one owner at a time.)
- 当所有者(变量)离开作用域时,这个值将被丢弃。(When the owner goes out of scope, the value will be dropped.)
第1条对应所有者(Owner)的概念,第2条对应所有权的转移(Move),第3条对应内存释放(Drop)。
学习了Rust的3条所有权规则之后,再来看前面的示例代码,当代码的第4行调用了find函数,根据所有权规则2堆上数据hello在同一时刻只能有一个所有者,调用find函数时,所有权将发生转移,堆上数据hello的所有者由main函数中的word变成了find函数中的s,word中的值(ptr, len, capacity)被移动到了s中,main函数中的word变量会失效,Rust的编译器会保证main函数中随后的代码再也无法使用变量word,这就保证了堆上数据的单一所有权,堆上数据的内存只有唯一的引用。如下图所示,可解读为word被移动(Move)到了s中:
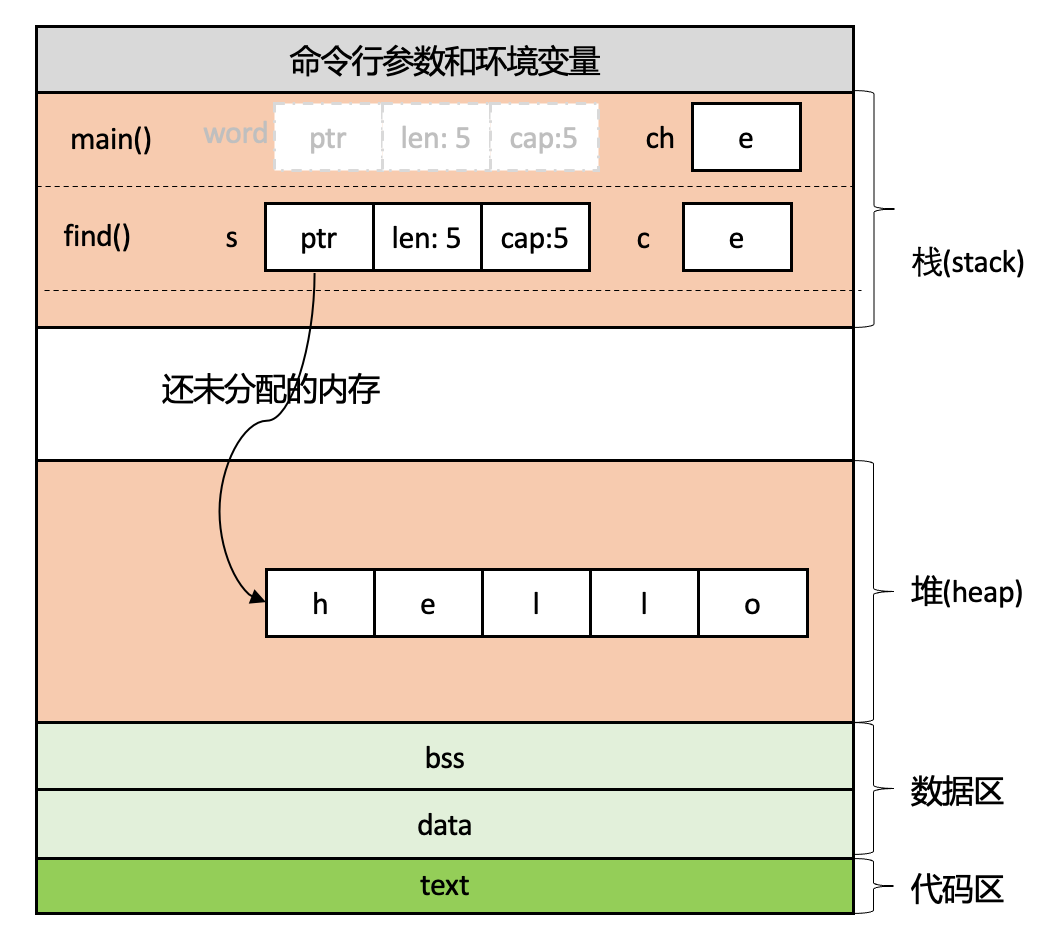
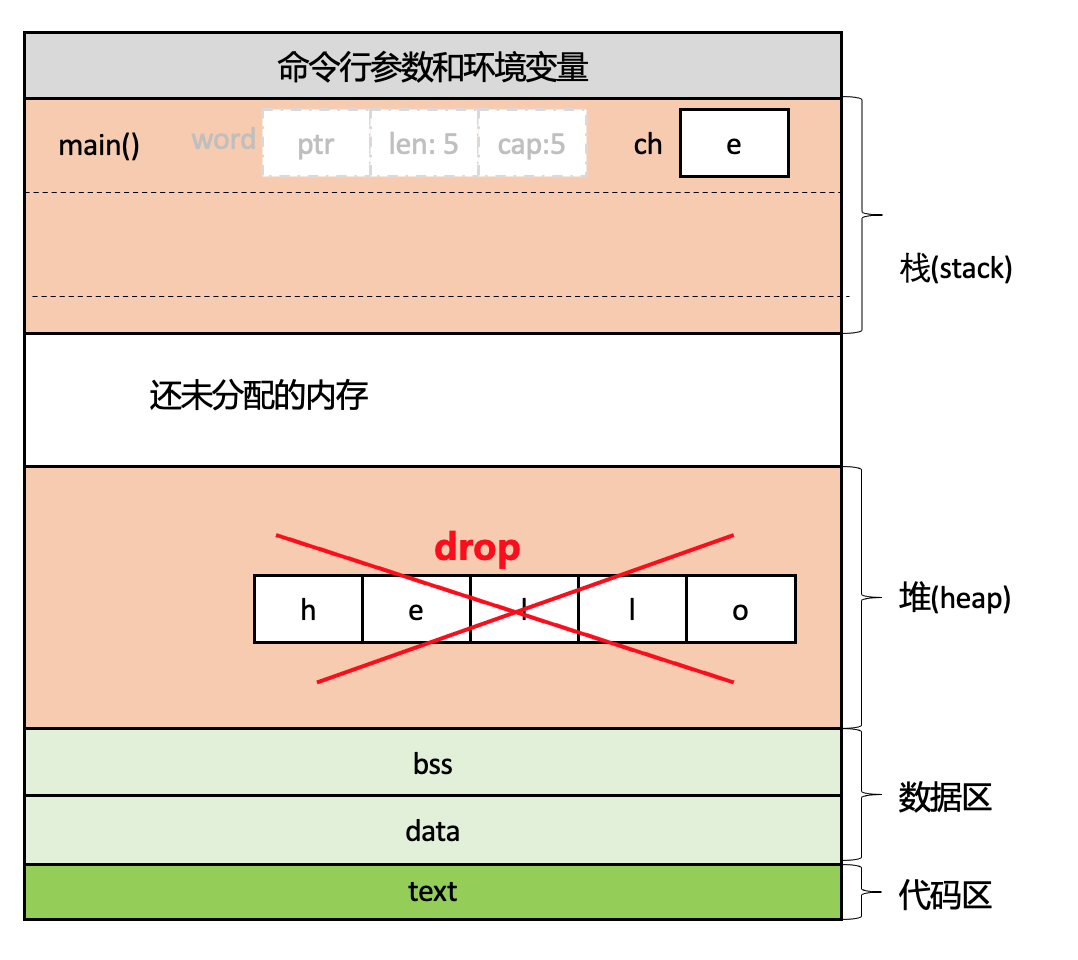
继续看前面的示例代码,当代码执行到第5行,find函数已经执行完成并返回到了main函数中,find函数中的变量s也离开了作用域,即s作为堆上数据hello的所有者离开了作用域,根据所有权规则3,当所有者离开作用域时,其引用的值将被丢弃,Rust会自动调用类型(这里是String)的drop函数清理堆内存。此时内存布局如下图所示,解读为堆内存数据不再有所有者,被丢弃(Drop):
总结
本文结合示例代码和示例代码执行过程中的内存示意图学习了Rust所有权规则、Move、Drop:
- Rust中的每个值都有一个所有者(owner)
- 一个值在同一时刻只能有一个所有者(move)
- 当所有者离开作用域时,其拥有的值将被丢弃(drop)