HDFS被设计成支持非常大的文件,与HDFS兼容的应用是那些处理大数据集的应用。这些应用程序处理非常大的文件在具有只被创建和写入一次,被读取一次或多次的特性,即HDFS中存储的大文件是一次写入多次读取不支持修改的,同时要求HDFS满足应用程序以流读取速度的要求。
正是因为大数据系统对所需的文件系统有这些要求,就决定了HDFS在存储模型上具有以下特点:
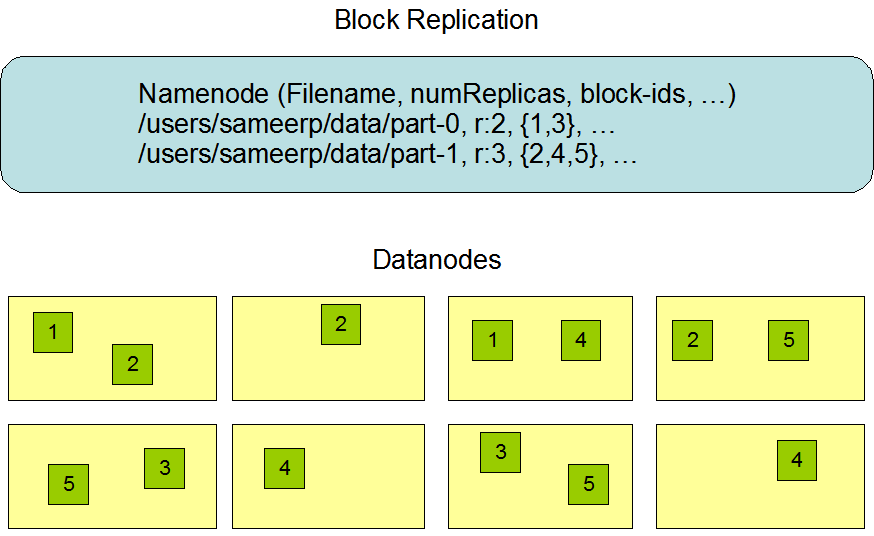
- HDFS是一个分布式文件系统,文件以线性按字节被切割成block(块),分散存储到HDFS集群的DataNode节点中,block在集群中就有了location(位置)
- 文件被线性按字节切割成block存储,block具有offset和id。一个文件除了最后一个block,其他block一定是大小一样的
- HDFS使用的典型block的大小是128MB,但HDFS的block大小可以根据硬件的I/O特性调整
- block具有副本(replication),block的副本不能出现在同一个节点上,但block副本没有主从的概念(这点要和其他分布式系统区分理解,例如ES的分片具有主从和副本的概念)
- 在向HDFS中上传文件时可以指block的大小和副本数量,副本是满足HDFS中存储的文件可靠性和性能的关键指标
- 根据HDFS write-once-read-many的特性,block的大小在文件上传后就不能修改了(支持追加数据),但是在文件上传后可以修改block的副本数量。