Prometheus是一个开源的监控系统和时序数据库。 Prometheus使用Go语言开发,是Google BorgMon监控系统的类似实现。
Prometheus架构
Prometheus使用的是Pull模型,Prometheus Server通过HTTP的pull方式到各个目标拉取监控数据。
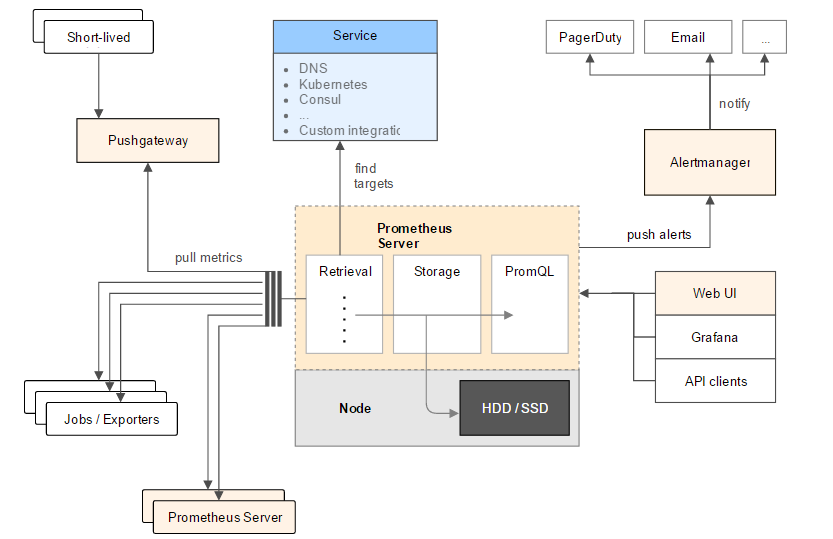
- Retrieval:中定义了Prometheus Server需要从哪些地方拉取数据
- Jobs / Exporters:Prometheus可以从Jobs或Exporters中拉取监控数据。Exporter以Web API的形式对外暴露数据采集接口。
- Prometheus Server:Prometheus还可以从其他的Prometheus Server中拉取数据
- Pushgateway:对于一些以临时性Job运行的组件,Prometheus可能还没有来得及从中pull监控数据的情况下,这些Job已经结束了,Job运行时可以在运行时将监控数据推送到Pushgateway中,Prometheus从Pushgateway中拉取数据,防止监控数据丢失
- Service:是指Prometheus可以动态的发现一些服务,拉取数据进行监控,如从DNS,Kubernetes,Consul中发现
- Storage:即Prometheus的存储,利用Prometheus Server的本地存储
- PromQL:是Prometheus的查询语句,利用PromQL可以和一些WEBUI(如Grafana)集成
- AlertManager:是一个独立于Prometheus的外部组件,用于监控系统的告警,通过配置文件可以配置一些告警规则,Prometheus会把告警推送到AlertManager。
监控数据模型
Prometheus 的数据模型支持多维自定义,这个模型下的时序数据有metric名和一组key/value标签组成。 Prometheus的存储都是按时间序列去实现的,相同的metrics名和label组成一条时间序列,如果label不同表示不同的时间序列。
<metric name>{<label name>=<label value>, ...}例如:api_http_requests_total{method="POST", handler="/messages"}
metric name即指标名称:我们需要给监测对象的指标取一个名字,例如api_http_requests_total。label即标签,表示对一条时间序列不同维度的识别,例如对于api_http_requests_total{method="POST", handler="/messages"}中有method表示请求用的是GET还是POST
- 指标名称和标签的命名规范可以参考METRIC AND LABEL NAMING
- 相同指标名称的数据模型无论增加或减少标签都会形成一条新的时间序列。对应关系型数据库来理解时序数据:
- 指标名称对应表名
- 标签对应表的字段,另外指标也是一个字段
- timestamp是表数据的主键
- 指标的值就是指标字段数据的值
时序样本(Samples)是按照某个时序以时间维度采集的数据,每个时序样本的组成如下:
- 一个float64的值
- 一个毫秒精度的unix时间戳
Metric Type
Prometheus的时序数据包含以下四种类型:
- Counter: 用于累计计数,例如用来记录请求次数。Counter的特点是一直增加不会减少。
- Gauge:用于记录常规数值,可以增加或减少。例如用来记录CPU、内存的变化
- Histogram:可理解为直方图,常用于跟踪事件发生的规模,如请求耗时、响应大小。可对记录的内容分组和聚合(count,sum等),例如响应时间小于500毫秒的多少次、500毫秒~1000毫秒之间多少次、1000毫秒以上的多少次
- Summary:与Histogram类似,但支持按百分比跟踪结果
Job和Instance
在Prometheus中任何被采集的目标Target被称为Instance,通常对应单个进程。 相同类型的Instance被称为Job,例如:
- job: api-server
- instance 1: 1.2.3.4:5670
- instance 2: 1.2.3.4:5671
- instance 3: 5.6.7.8:5670
- instance 4: 5.6.7.8:5671Prometheus在从目标采集数据时会自动附加一些标签,用于识别被采集的目标:
- job:配置的job名称
- instance:
<host>:<port>