我们已经可以很方便的使用kubeadm快速初始化Kubernetes集群,但kubeadm当前还不能用于生产环境,同时kubeadm初始化的集群的Master节点不是高可用的,后端存储etcd也是单点。因此,本文将基于Kubernetes二进制包手动部署一个高可用的Kubernetes 1.6集群,将启用ApiServer的TLS双向认证和RBAC授权等安全机制。 通过这个手动部署的过程,我们还可以更加深入理解Kubernetes各组件的交互和运行原理。
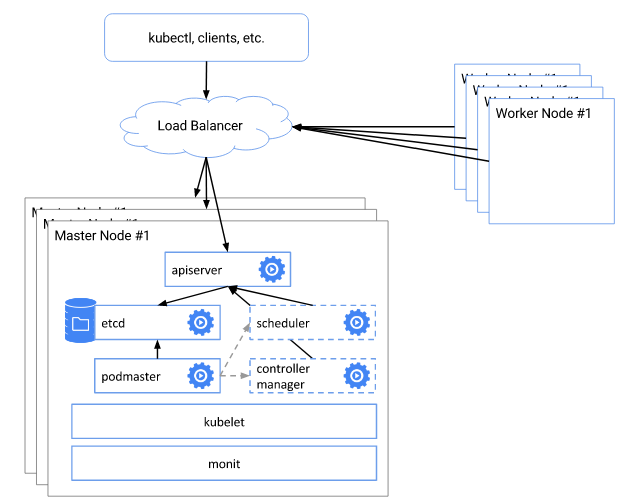
1. 环境准备
1.1 系统环境
操作系统CentOS 7.3
192.168.61.11 node1
192.168.61.12 node2
192.168.61.13 node31.2 安装包下载
从这里下载kubernetes二进制安装包:
wget https://dl.k8s.io/v1.6.2/kubernetes-server-linux-amd64.tar.gz
tar -zxvf kubernetes-server-linux-amd64.tar.g1.3 系统配置
在各节点创建/etc/sysctl.d/k8s.conf文件,添加如下内容:
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1执行sysctl -p /etc/sysctl.d/k8s.conf使修改生效。
禁用selinux:
setenforce 0
vi /etc/selinux/config
SELINUX=disabled1.3 etcd高可用集群部署
Kubernetes使用etcd作为ApiServer的持久化存储,因此需要部署高可用的etcd集群,安全要求我们为etcd集群开启TLS通信和认证。 在node1~node3三个节点上部署etcd集群,这里不再展开,可参考前面写的一篇《etcd 3.1 高可用集群搭建》。
最终部署的etcd集群如下:
node1 https://192.168.61.11:2379
node2 https://192.168.61.12:2379
node3 https://192.168.61.13:23791.4 在各节点安装Docker
在集群各个服务器节点上安装Docker。根据最近的文档Kubernetes 1.6还没有针对docker 1.13和最新的docker 17.03上做测试和验证,所以这里安装Kubernetes官方推荐的Docker 1.12版本。Docker的安装比较简单,这里也不展开,可参考《使用kubeadm安装Kubernetes 1.6》中的“安装Docker 1.12”章节。
2. Kubernetes各组件TLS证书和密钥
我们将禁用kube-apiserver的HTTP端口,启用Kubernetes集群相关组件的TLS通信和双向认证,下面将使用工具生成各组件TLS的证书和私钥。
我们将使用cfssl生成所需要的私钥和证书。 cfssl在《etcd 3.1 高可用集群搭建》中已经用过,这里直接使用。
2.1 CA证书和私钥
复用《etcd 3.1 高可用集群搭建》中使用的ca-config.json:
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"frognew": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "87600h"
}
}
}
}创建CA证书签名请求配置ca-csr.json:
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "cloudnative"
}
]
}CN即Common Name,kube-apiserver从证书中提取该字段作为请求的用户名O即Organization,kube-apiserver 从证书中提取该字段作为请求用户所属的组
下面使用cfss生成CA证书和私钥:
cfssl gencert -initca ca-csr.json | cfssljson -bare cals
ca-config.json ca.csr ca-csr.json ca-key.pem ca.pemca-key.pem和ca.pem需要保存在一个安全的地方,后边会用到。
2.2 创建kube-apiserver证书和私钥
创建kube-apiserver证书签名请求配置apiserver-csr.json:
{
"CN": "kubernetes",
"hosts": [
"127.0.0.1",
"192.168.61.10",
"192.168.61.11",
"192.168.61.12",
"192.168.61.13",
"10.96.0.1",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "k8s",
"OU": "cloudnative"
}
]
}注意上面配置hosts字段中指定授权使用该证书的IP和域名列表,因为现在要生成的证书需要被Kubernetes Master集群各个节点使用,所以这里指定了各个节点的IP和hostname。
另外,我们为了实现kube-apiserver的高可用,我们将在其前面部署一个高可用的负载均衡器,Kubernetes的一些核心组件,通过这个负载均衡器和apiserver进行通信,因此这里在证书请求配置的hosts字段中还要加上这个负载均衡器的IP地址,这里是192.168.61.10。
同时还要指定集群内部kube-apiserver的多个域名和IP地址10.96.0.1(后边kube-apiserver-service-cluster-ip-range=10.96.0.0/12参数的指定网段的第一个IP)。
下面生成kube-apiserver的证书和私钥:
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=frognew apiserver-csr.json | cfssljson -bare apiserver
ls apiserver*
apiserver.csr apiserver-csr.json apiserver-key.pem apiserver.pem2.3 创建kubernetes-admin客户端证书和私钥
创建admin证书的签名请求配置admin-csr.json:
{
"CN": "kubernetes-admin",
"hosts": [
"192.168.61.11",
"192.168.61.12",
"192.168.61.13"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "system:masters",
"OU": "cloudnative"
}
]
}kube-apiserver将提取CN作为客户端的用户名,这里是kubernetes-admin,将提取O作为用户所属的组,这里是system:master。
kube-apiserver预定义了一些 RBAC使用的ClusterRoleBindings,例如 cluster-admin将组system:masters与 ClusterRole cluster-admin绑定,而cluster-admin拥有访问kube-apiserver的所有权限,因此kubernetes-admin这个用户将作为集群的超级管理员。
了解Kubernetes的RBAC和ApiServer的认证的内容可参考之前写过的两篇《Kubernetes 1.6新特性学习:RBAC授权》和《Kubernetes集群安全:Api Server认证》。
下面生成kubernetes-admin的证书和私钥:
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=frognew admin-csr.json | cfssljson -bare admin
ls admin*
admin.csr admin-csr.json admin-key.pem admin.pem2.4 创建kube-controller-manager客户端证书和私钥
下面创建kube-controller-manager客户端访问ApiServer所需的证书和私钥。 controller-manager证书的签名请求配置controller-manager-csr.json:
{
"CN": "system:kube-controller-manager",
"hosts": [
"192.168.61.11",
"192.168.61.12",
"192.168.61.13"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "system:kube-controller-manager",
"OU": "cloudnative"
}
]
}kube-apiserver将提取CN作为客户端的用户名,这里是system:kube-controller-manager。
kube-apiserver预定义的 RBAC使用的ClusterRoleBindings system:kube-controller-manager将用户system:kube-controller-manager与ClusterRole system:kube-controller-manager绑定。
下面生成证书和私钥:
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=frognew controller-manager-csr.json | cfssljson -bare controller-manager
ls controller-manager*
controller-manager.csr controller-manager-csr.json controller-manager-key.pem controller-manager.pem2.5 创建kube-scheduler客户端证书和私钥
下面创建kube-scheduler客户端访问ApiServer所需的证书和私钥。 scheduler证书的签名请求配置scheduler-csr.json:
{
"CN": "system:kube-scheduler",
"hosts": [
"192.168.61.11",
"192.168.61.12",
"192.168.61.13"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "system:kube-scheduler",
"OU": "cloudnative"
}
]
}kube-scheduler将提取CN作为客户端的用户名,这里是system:kube-scheduler。
kube-apiserver预定义的RBAC使用的ClusterRoleBindings system:kube-scheduler将用户system:kube-scheduler与ClusterRole system:kube-scheduler绑定。
下面生成证书和私钥:
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=frognew scheduler-csr.json | cfssljson -bare scheduler
ls scheduler*
scheduler.csr scheduler-csr.json scheduler-key.pem scheduler.pem3. Kubernetes Master集群部署
部署的Master节点集群由Node1, Node2, Node3三个节点组成,每个节点上部署kube-apiserver,kube-controller-manager,kube-scheduler三个核心组件。 kube-apiserver的3个实例同时提供服务,在其前端部署一个高可用的负载均衡器作为kube-apiserver的地址。 kube-controller-manager和kube-scheduler也是各自3个实例,在同一时刻只能有1个实例工作,这个实例通过选举产生。
将前面生成的 ca.pem, apiserver-key.pem, apiserver.pem, admin.pem, admin-key.pem, controller-manager.pem, controller-manager-key.pem, scheduler-key.pem, scheduler.pem拷贝到各个节点的/etc/kubernetes/pki目录下:
mkdir -p /etc/kubernetes/pki
cp {ca.pem,apiserver-key.pem,apiserver.pem,admin.pem, admin-key.pem, controller-manager.pem, controller-manager-key.pem,scheduler-key.pem, scheduler.pem} /etc/kubernetes/pki将Kubernetes二进制包解压后kubernetes/server/bin中的kube-apiserver,kube-controller-manager,kube-scheduler,kubectl,kube-proxy,kubelet拷贝到各节点的/usr/local/bin目录中:
cp {kube-apiserver,kube-controller-manager,kube-scheduler,kubectl,kube-proxy,kubelet} /usr/local/bin/3.1 kube-apiserver部署
创建kube-apiserver的systemd unit文件/usr/lib/systemd/system/kube-apiserver.service,注意替换INTERNAL_IP变量的值:
mkdir -p /var/log/kubernetes
export INTERNAL_IP=192.168.61.11
cat > /usr/lib/systemd/system/kube-apiserver.service <<EOF
[Unit]
Description=kube-apiserver
After=network.target
After=etcd.service
[Service]
EnvironmentFile=-/etc/kubernetes/apiserver
ExecStart=/usr/local/bin/kube-apiserver \
--logtostderr=true \
--v=0 \
--advertise-address=${INTERNAL_IP} \
--bind-address=${INTERNAL_IP} \
--secure-port=6443 \
--insecure-port=0 \
--allow-privileged=true \
--etcd-servers=https://192.168.61.11:2379,https://192.168.61.12:2379,https://192.168.61.13:2379 \
--etcd-cafile=/etc/etcd/ssl/ca.pem \
--etcd-certfile=/etc/etcd/ssl/etcd.pem \
--etcd-keyfile=/etc/etcd/ssl/etcd-key.pem \
--storage-backend=etcd3 \
--service-cluster-ip-range=10.96.0.0/12 \
--tls-cert-file=/etc/kubernetes/pki/apiserver.pem \
--tls-private-key-file=/etc/kubernetes/pki/apiserver-key.pem \
--client-ca-file=/etc/kubernetes/pki/ca.pem \
--service-account-key-file=/etc/kubernetes/pki/ca-key.pem \
--experimental-bootstrap-token-auth=true \
--apiserver-count=3 \
--enable-swagger-ui=true \
--admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,PersistentVolumeLabel,DefaultStorageClass,ResourceQuota,DefaultTolerationSeconds \
--authorization-mode=RBAC \
--audit-log-maxage=30 \
--audit-log-maxbackup=3 \
--audit-log-maxsize=100 \
--audit-log-path=/var/log/kubernetes/audit.log
Restart=on-failure
Type=notify
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF--insecure-port禁用了不安全的http端口--secure-port指定https安全端口,kube-scheduler、kube-controller-manager、kubelet、kube-proxy、kubectl等组件都将使用安全端口与ApiServer通信(实际上会由我们在前端部署的负载均衡器代理)。--authorization-mode=RBAC表示在安全端口启用RBAC授权模式,在授权过程会拒绝会授权的请求。kube-scheduler、kube-controller-manager、kubelet、kube-proxy、kubectl等组件都使用各自证书或kubeconfig指定相关的User、Group来通过RBAC授权。--admission-control为准入机制,这里配置了NamespaceLifecycle,LimitRanger,ServiceAccount,PersistentVolumeLabel,DefaultStorageClass,ResourceQuota,DefaultTolerationSeconds--service-cluster-ip-range指定Service Cluster IP的地址段,注意该地址段是Kubernetes Service使用的,是虚拟IP,从外部不能路由可达。
启动kube-apiserver:
systemctl daemon-reload
systemctl enable kube-apiserver
systemctl start kube-apiserver
systemctl status kube-apiserver3.2 配置kubectl访问apiserver
我们已经部署了kube-apiserver,并且前面已经kubernetes-admin的证书和私钥,我们将使用这个用户访问ApiServer。
kubectl --server=https://192.168.61.11:6443 \
--certificate-authority=/etc/kubernetes/pki/ca.pem \
--client-certificate=/etc/kubernetes/pki/admin.pem \
--client-key=/etc/kubernetes/pki/admin-key.pem \
get componentstatuses
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get http://127.0.0.1:10251/healthz: dial tcp 127.0.0.1:10251: getsockopt: connection refused
controller-manager Unhealthy Get http://127.0.0.1:10252/healthz: dial tcp 127.0.0.1:10252: getsockopt: connection refused
etcd-0 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}上面我们使用kubectl命令打印出了Kubernetes核心组件的状态,因为我们还没有部署kube-scheduler和controller-manager,所以这两个组件当前是不健康的。
前面面使用kubectl时需要指定ApiServer的地址以及客户端的证书,用起来比较繁琐。 接下来我们创建kubernetes-admin的kubeconfig文件 admin.conf。
cd /etc/kubernetes
export KUBE_APISERVER="https://192.168.61.11:6443"
# set-cluster
kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/pki/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=admin.conf
# set-credentials
kubectl config set-credentials kubernetes-admin \
--client-certificate=/etc/kubernetes/pki/admin.pem \
--embed-certs=true \
--client-key=/etc/kubernetes/pki/admin-key.pem \
--kubeconfig=admin.conf
# set-context
kubectl config set-context kubernetes-admin@kubernetes \
--cluster=kubernetes \
--user=kubernetes-admin \
--kubeconfig=admin.conf
# set default context
kubectl config use-context kubernetes-admin@kubernetes --kubeconfig=admin.conf为了使用kubectl访问apiserver使用admin.conf,将其拷贝到$HOME/.kube中并重命名成config:
cp /etc/kubernetes/admin.conf ~/.kube/config尝试直接使用kubectl命令访问apiserver:
kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get http://127.0.0.1:10251/healthz: dial tcp 127.0.0.1:10251: getsockopt: connection refused
controller-manager Unhealthy Get http://127.0.0.1:10252/healthz: dial tcp 127.0.0.1:10252: getsockopt: connection refused
etcd-0 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}因为我们已经把kubernetes-admin用户的相关信息和证书保存到了admin.conf中,所以可以删除/etc/kubernetes/pki中的admin.pem和admin-key.pem:
cd /etc/kubernetes/pki
rm -f admin.pem admin-key.pem3.3 kube-apiserver高可用
经过前面的步骤,我们已经在node1,node2,node3上部署了Kubernetes Master节点的kube-apiserver,地址如下:
https://192.168.61.11:6443
https://192.168.61.12:6443
https://192.168.61.13:6443为了实现高可用,可以在前面放一个负载均衡器来代理访问kube-apiserver的请求,再对负载均衡器实现高可用。 例如,HAProxy+Keepavlided,我们在node1~node3这3个Master节点上运行keepalived和HAProxy,3个keepalived争抢同一个VIP地址,3个HAProxy也都尝试去绑定到这个VIP的同一个端口。 例如:192.168.61.10:5000,当某个Haproxy出现异常后,其他节点上的Keepalived会争抢到VIP,同时这个节点上HAProxy会接管流量。
HAProxy+Keepavlided的部署这里不再展开。 最终kube-apiserver高可用的地址为https://192.168.61.10:5000,修改前面$HOME/.kube/config中的clusters:cluster:server的值为这个地址。
kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get http://127.0.0.1:10251/healthz: dial tcp 127.0.0.1:10251: getsockopt: connection refused
controller-manager Unhealthy Get http://127.0.0.1:10252/healthz: dial tcp 127.0.0.1:10252: getsockopt: connection refused
etcd-0 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}3.4 kube-controller-manager部署
前面已经创建了controller-manager.pem和controller-manage-key.pem,下面生成controller-manager的kubeconfig文件controller-manager.conf:
cd /etc/kubernetes
export KUBE_APISERVER="https://192.168.61.10:5000"
# set-cluster
kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/pki/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=controller-manager.conf
# set-credentials
kubectl config set-credentials system:kube-controller-manager \
--client-certificate=/etc/kubernetes/pki/controller-manager.pem \
--embed-certs=true \
--client-key=/etc/kubernetes/pki/controller-manager-key.pem \
--kubeconfig=controller-manager.conf
# set-context
kubectl config set-context system:kube-controller-manager@kubernetes \
--cluster=kubernetes \
--user=system:kube-controller-manager \
--kubeconfig=controller-manager.conf
# set default context
kubectl config use-context system:kube-controller-manager@kubernetes --kubeconfig=controller-manager.confcontroller-manager.conf文件生成后将这个文件分发到各个Master节点的/etc/kubernetes目录下。
创建kube-controller-manager的systemd unit文件/usr/lib/systemd/system/kube-controller-manager.service:
export KUBE_APISERVER="https://192.168.61.10:5000"
cat > /usr/lib/systemd/system/kube-controller-manager.service <<EOF
[Unit]
Description=kube-controller-manager
After=network.target
After=kube-apiserver.service
[Service]
EnvironmentFile=-/etc/kubernetes/controller-manager
ExecStart=/usr/local/bin/kube-controller-manager \
--logtostderr=true \
--v=0 \
--master=${KUBE_APISERVER} \
--kubeconfig=/etc/kubernetes/controller-manager.conf \
--cluster-name=kubernetes \
--cluster-signing-cert-file=/etc/kubernetes/pki/ca.pem \
--cluster-signing-key-file=/etc/kubernetes/pki/ca-key.pem \
--service-account-private-key-file=/etc/kubernetes/pki/ca-key.pem \
--root-ca-file=/etc/kubernetes/pki/ca.pem \
--insecure-experimental-approve-all-kubelet-csrs-for-group=system:bootstrappers \
--use-service-account-credentials=true \
--service-cluster-ip-range=10.96.0.0/12 \
--cluster-cidr=10.244.0.0/16 \
--allocate-node-cidrs=true \
--leader-elect=true \
--controllers=*,bootstrapsigner,tokencleaner
Restart=on-failure
Type=simple
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF--service-cluster-ip-range和kube-api-server中指定的参数值一致
在各节点上启动:
systemctl daemon-reload
systemctl enable kube-controller-manager
systemctl start kube-controller-manager
systemctl status kube-controller-manager在node1,node2,node3上完成部署和启动后,查看一下状态:
kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get http://127.0.0.1:10251/healthz: dial tcp 127.0.0.1:10251: getsockopt: connection refused
controller-manager Healthy ok
etcd-1 Healthy {"health": "true"}
etcd-2 Healthy {"health": "true"}
etcd-0 Healthy {"health": "true"}到这一步三个Master节点上的kube-controller-manager部署完成,通过选举出一个leader工作。 分别在三个节点查看状态:
#node1
systemctl status -l kube-controller-manager
......
...... attempting to acquire leader lease...
#node2
systemctl status -l kube-controller-manager
......
...... controllermanager.go:437] Started "endpoint"
...... controllermanager.go:437] Started "replicationcontroller"
...... replication_controller.go:150] Starting RC Manager
...... controllermanager.go:437] Started "replicaset"
...... replica_set.go:155] Starting ReplicaSet controller
...... controllermanager.go:437] Started "disruption"
...... disruption.go:269] Starting disruption controller
...... controllermanager.go:437] Started "statefuleset"
...... stateful_set.go:144] Starting statefulset controller
...... controllermanager.go:437] Started "bootstrapsigner"
#node3
systemctl status -l kube-controller-manager
......
...... attempting to acquire leader lease...从输出的日志可以看出现在第二个节点上的kube-controller-manager。
3.5 kube-scheduler部署
前面已经创建了scheduler.pem和scheduler-key.pem,下面生成kube-scheduler的kubeconfig文件scheduler.conf:
cd /etc/kubernetes
export KUBE_APISERVER="https://192.168.61.10:5000"
# set-cluster
kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/pki/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=scheduler.conf
# set-credentials
kubectl config set-credentials system:kube-scheduler \
--client-certificate=/etc/kubernetes/pki/scheduler.pem \
--embed-certs=true \
--client-key=/etc/kubernetes/pki/scheduler-key.pem \
--kubeconfig=scheduler.conf
# set-context
kubectl config set-context system:kube-scheduler@kubernetes \
--cluster=kubernetes \
--user=system:kube-scheduler \
--kubeconfig=scheduler.conf
# set default context
kubectl config use-context system:kube-scheduler@kubernetes --kubeconfig=scheduler.confscheduler.conf文件生成后将这个文件分发到各个Master节点的/etc/kubernetes目录下。
创建kube-scheduler的systemd unit文件/usr/lib/systemd/system/kube-scheduler.service:
export KUBE_APISERVER="https://192.168.61.10:5000"
cat > /usr/lib/systemd/system/kube-scheduler.service <<EOF
[Unit]
Description=kube-scheduler
After=network.target
After=kube-apiserver.service
[Service]
EnvironmentFile=-/etc/kubernetes/scheduler
ExecStart=/usr/local/bin/kube-scheduler \
--logtostderr=true \
--v=0 \
--master=${KUBE_APISERVER} \
--kubeconfig=/etc/kubernetes/scheduler.conf \
--leader-elect=true
Restart=on-failure
Type=simple
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF在各节点上启动:
systemctl daemon-reload
systemctl enable kube-scheduler
systemctl start kube-scheduler
systemctl status kube-scheduler到这一步三个Master节点上的kube-scheduler部署完成,通过选举出一个leader工作。
查看Kubernetes Master集群各个核心组件的状态全部正常。
kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-2 Healthy {"health": "true"}
etcd-0 Healthy {"health": "true"}
etcd-1 Healthy {"health": "true"}4. Kubernetes Node节点部署
Kubernetes的一个Node节点上需要运行如下组件:
- Docker,这个我们前面在做环境准备的时候已经在各节点部署和运行了
- kubelet
- kube-proxy
下面我们以在node1上为例部署这些组件:
4.1 CNI安装
wget https://github.com/containernetworking/cni/releases/download/v0.5.2/cni-amd64-v0.5.2.tgz
mkdir -p /opt/cni/bin
tar -zxvf cni-amd64-v0.5.2.tgz -C /opt/cni/bin
ls /opt/cni/bin/
bridge cnitool dhcp flannel host-local ipvlan loopback macvlan noop ptp tuning4.2 kubelet部署
首先确认将kubelet的二进制文件拷贝到/usr/local/bin下。 创建kubelet的工作目录:
mkdir -p /var/lib/kubelet安装依赖包:
yum install ebtables socat util-linux conntrack-tools接下来创建访问ApiServer的证书和私钥,kubelet-csr.json:
{
"CN": "system:node:node1",
"hosts": [
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "system:nodes",
"OU": "cloudnative"
}
]
}- 注意CN为用户名,使用
system:node:<node-name> - O为用户组,Kubernetes RBAC定义了ClusterRoleBinding将Group system:nodes和ClusterRole system:node关联。
生成证书和私钥:
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=frognew kubelet-csr.json | cfssljson -bare kubelet
ls kubelet*
kubelet.csr kubelet-csr.json kubelet-key.pem kubelet.pem生成kubeconfig文件kubelet.conf:
cd /etc/kubernetes
export KUBE_APISERVER="https://192.168.61.10:5000"
# set-cluster
kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/pki/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=kubelet.conf
# set-credentials
kubectl config set-credentials system:node:node1 \
--client-certificate=/etc/kubernetes/pki/kubelet.pem \
--embed-certs=true \
--client-key=/etc/kubernetes/pki/kubelet-key.pem \
--kubeconfig=kubelet.conf
# set-context
kubectl config set-context system:node:node1@kubernetes \
--cluster=kubernetes \
--user=system:node:node1 \
--kubeconfig=kubelet.conf
# set default context
kubectl config use-context system:node:node1@kubernetes --kubeconfig=kubelet.conf创建kubelet的systemd unit service文件,注意替换NodeIP变量:
export KUBE_APISERVER="https://192.168.61.10:5000"
export NodeIP="192.168.61.11"
cat > /usr/lib/systemd/system/kubelet.service <<EOF
[Unit]
Description=kubelet
After=docker.service
Requires=docker.service
[Service]
WorkingDirectory=/var/lib/kubelet
EnvironmentFile=-/etc/kubernetes/kubelet
ExecStart=/usr/local/bin/kubelet \
--logtostderr=true \
--v=0 \
--address=${NodeIP} \
--api-servers==${KUBE_APISERVER} \
--cluster-dns=10.96.0.10 \
--cluster-domain=cluster.local \
--kubeconfig=/etc/kubernetes/kubelet.conf \
--require-kubeconfig=true \
--pod-manifest-path=/etc/kubernetes/manifests \
--allow-privileged=true \
--authorization-mode=AlwaysAllow \
# --authorization-mode=Webhook \
# --client-ca-file=/etc/kubernetes/pki/ca.pem \
--network-plugin=cni \
--cni-conf-dir=/etc/cni/net.d \
--cni-bin-dir=/opt/cni/bin
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF--pod-manifest-path=/etc/kubernetes/manifests指定了静态Pod定义的目录。可以提前创建好这个目录mkdir -p /etc/kubernetes/manifests。关于静态Pod的内容可参考之前写的一篇《Kubernetes资源对象之Pod》中的静态Pod的内容。--authorization-mode=AlwaysAllow这里并没有启用Kubernetes 1.5的新特性即kubelet API的认证授权功能,先设置AlwaysAllow和我们的线上环境保持一致
启动kubelet:
systemctl daemon-reload
systemctl enable kubelet
systemctl start kubelet
systemctl status kubeletkubectl get nodes
NAME STATUS AGE VERSION
node1 NotReady 35s v1.6.24.3 kube-proxy部署
首先确认已经将kuber-proxy的二进制文件拷贝到/usr/local/bin下。 创建kubelet的工作目录:
mkdir -p /var/lib/kube-proxy接下来创建访问ApiServer的证书和私钥,kube-proxy-csr.json:
{
"CN": "system:kube-proxy",
"hosts": [
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "BeiJing",
"L": "BeiJing",
"O": "system:kube-proxy",
"OU": "cloudnative"
}
]
}- CN 指定该证书的 User为 system:kube-proxy。Kubernetes RBAC定义了ClusterRoleBinding将system:kube-proxy用户与system:node-proxier 角色绑定。system:node-proxier具有kube-proxy组件访问ApiServer的相关权限。
生成证书和私钥:
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=frognew kube-proxy-csr.json | cfssljson -bare kube-proxy
ls kube-proxy*
kube-proxy.csr kube-proxy-csr.json kube-proxy-key.pem kube-proxy.pem生成kubeconfig文件kube-proxy.conf:
cd /etc/kubernetes
export KUBE_APISERVER="https://192.168.61.10:5000"
# set-cluster
kubectl config set-cluster kubernetes \
--certificate-authority=/etc/kubernetes/pki/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=kube-proxy.conf
# set-credentials
kubectl config set-credentials system:kube-proxy \
--client-certificate=/etc/kubernetes/pki/kube-proxy.pem \
--embed-certs=true \
--client-key=/etc/kubernetes/pki/kube-proxy-key.pem \
--kubeconfig=kube-proxy.conf
# set-context
kubectl config set-context system:kube-proxy@kubernetes \
--cluster=kubernetes \
--user=system:kube-proxy \
--kubeconfig=kube-proxy.conf
# set default context
kubectl config use-context system:kube-proxy@kubernetes --kubeconfig=kube-proxy.conf创建kube-proxy的systemd unit service文件,注意替换NodeIP变量:
export KUBE_APISERVER="https://192.168.61.10:5000"
export NodeIP="192.168.61.11"
cat > /usr/lib/systemd/system/kube-proxy.service <<EOF
[Unit]
Description=kube-proxy
After=network.target
[Service]
WorkingDirectory=/var/lib/kube-proxy
EnvironmentFile=-/etc/kubernetes/kube-proxy
ExecStart=/usr/local/bin/kube-proxy \
--logtostderr=true \
--v=0 \
--bind-address=${NodeIP} \
--kubeconfig=/etc/kubernetes/kube-proxy.conf \
--cluster-cidr=10.244.0.0/16
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF启动kubelet-proxy:
systemctl daemon-reload
systemctl enable kube-proxy
systemctl start kube-proxy
systemctl status -l kube-proxy4.4 部署Pod Network插件flannel
flannel以DaemonSet的形式运行在Kubernetes集群中。 由于我们的etcd集群启用了TLS认证,为了从flannel容器中能访问etcd,我们先把etcd的TLS证书信息保存到Kubernetes的Secret中。
kubectl create secret generic etcd-tls-secret --from-file=/etc/etcd/ssl/etcd.pem --from-file=/etc/etcd/ssl/etcd-key.pem --from-file=/etc/etcd/ssl/ca.pem -n kube-system
kubectl describe secret etcd-tls-secret -n kube-system
Name: etcd-tls-secret
Namespace: kube-system
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
etcd-key.pem: 1675 bytes
etcd.pem: 1489 bytes
ca.pem: 1330 bytesmkdir -p ~/k8s/flannel
cd ~/k8s/flannel
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel-rbac.yml
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml对kube-flannel.yml做以下修改:
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
......
spec:
template:
metadata:
......
spec:
......
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.7.1-amd64
command: [
"/opt/bin/flanneld",
"--ip-masq",
"--kube-subnet-mgr",
"-etcd-endpoints=https://192.168.61.11:2379,https://192.168.61.12:2379,https://192.168.61.13:2379",
"-etcd-cafile=/etc/etcd/ssl/ca.pem",
"--etcd-certfile=/etc/etcd/ssl/etcd.pem",
"-etcd-keyfile=/etcd/etcd/ssl/etcd-key.pem",
"--iface=etn0" ]
securityContext:
privileged: true
......
volumeMounts:
......
- name: etcd-tls-secret
readOnly: true
mountPath: /etc/etcd/ssl/
......
volumes:
......
- name: etcd-tls-secret
secret:
secretName: etcd-tls-secret- flanneld的启动参数中加入以下参数
-etcd-endpoints配置etcd集群的访问地址-etcd-cafile配置etcd的CA证书,/etc/etcd/ssl/ca.pem从etcd-tls-secret这个Secret挂载--etcd-certfile配置etcd的公钥证书,/etc/etcd/ssl/etcd.pem从etcd-tls-secret这个Secret挂载--etcd-keyfile配置etcd的私钥,/etc/etcd/ssl/etcd-key.pem从etcd-tls-secret这个Secret挂载--iface当Node节点有多个网卡时用于指明具体的网卡名称
下面部署flannel:
kubectl create -f kube-flannel-rbac.yml
kubectl create -f kube-flannel.ymlkubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system kube-flannel-ds-dhz6m 2/2 Running 0 10s
ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.0.0 netmask 255.255.255.255 broadcast 0.0.0.0
ether c2:e6:ad:26:f5:f6 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 1 overruns 0 carrier 0 collisions 04.5 部署kube-dns插件
Kubernetes支持kube-dns以Cluster Add-On的形式运行。Kubernetes会在集群中调度一个DNS的Pod和Service。
mkdir -p ~/k8s/kube-dns
wget https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/dns/kubedns-cm.yaml
wget https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/dns/kubedns-sa.yaml
wget https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/dns/kubedns-svc.yaml.base
wget https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/dns/kubedns-controller.yaml.base
wget https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/dns/transforms2sed.sed查看transforms2sed.sed:
s/__PILLAR__DNS__SERVER__/$DNS_SERVER_IP/g
s/__PILLAR__DNS__DOMAIN__/$DNS_DOMAIN/g
s/__MACHINE_GENERATED_WARNING__/Warning: This is a file generated from the base underscore template file: __SOURCE_FILENAME__/g将$DNS_SERVER_IP替换成10.96.0.10,将DNS_DOMAIN替换成cluster.local.。
注意$DNS_SERVER_IP要和kubelet设置的--cluster-dns参数一致
执行:
cd ~/k8s/kube-dns
sed -f transforms2sed.sed kubedns-svc.yaml.base > kubedns-svc.yaml
sed -f transforms2sed.sed kubedns-controller.yaml.base > kubedns-controller.yaml- 上面的变量
DNS_SERVER要和kubelet设置的--cluster-dns参数一致。
kubectl create -f kubedns-cm.yaml
kubectl create -f kubedns-sa.yaml
kubectl create -f kubedns-svc.yaml
kubectl create -f kubedns-controller.yaml 查看kube-dns的Pod,确认所有Pod都处于Running状态:
kubectl get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system kube-dns-806549836-rv4mm 3/3 Running 0 12s
kube-system kube-flannel-ds-jnpg9 2/2 Running 0 5m测试一下DNS功能是否好用:
kubectl run curl --image=radial/busyboxplus:curl -i --tty
nslookup kubernetes.default
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: kubernetes
Address 1: 10.96.0.1 kubernetes.default.svc.cluster.localkube-dns是Kubernetes实现服务发现的重要组件之一,默认情况下只会创建一个DNS Pod,在生产环境中我们可能需要对kube-dns进行扩容。 有两种方式:
- 手动扩容
kubectl --namespace=kube-system scale deployment kube-dns --replicas=<NUM_YOU_WANT> - 使用DNS Horizontal Autoscaler
4.6 添加新的Node节点
重复4.1~4.3的步骤,添加新的Node节点。 在添加新节点时注意以下事项:
- 4.2中生成kubelet访问ApiServer的证书和私钥,以及基于证书生成kubeconfig文件时,CN用户名使用
system:node:<node-name>。每个Node节点是不同的。 - 4.3中不需要再生成kube-proxy访问ApiServer的证书和私钥,只需将已有Node节点上的kubeconfig文件kube-proxy.conf分发到新的节点上即可。
kubectl get nodes
NAME STATUS AGE VERSION
node1 Ready 2h v1.6.2
node2 Ready 12m v1.6.2
node3 Ready 10m v1.6.2注意生产环境是需要将Master节点隔离的,不建议在Master节点跑工作负载。因为测试环境机器有限,所以这里的Node节点也是node1~node3。
5. dashboard插件部署
mkdir -p ~/k8s/dashboard
cd ~/k8s/dashboard
wget https://raw.githubusercontent.com/kubernetes/dashboard/master/src/deploy/kubernetes-dashboard.yaml
kubectl create -f kubernetes-dashboard.yamlkubectl get pod,svc -n kube-system -l app=kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
po/kubernetes-dashboard-2457468166-5q9xk 1/1 Running 0 6m
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/kubernetes-dashboard 10.102.242.110 <nodes> 80:31632/TCP 6m6. heapster插件部署
下面安装Heapster为集群添加使用统计和监控功能,为Dashboard添加仪表盘。 使用InfluxDB做为Heapster的后端存储,开始部署:
mkdir -p ~/k8s/heapster
cd ~/k8s/heapster
wget https://raw.githubusercontent.com/kubernetes/heapster/master/deploy/kube-config/influxdb/grafana.yaml
wget https://raw.githubusercontent.com/kubernetes/heapster/master/deploy/kube-config/rbac/heapster-rbac.yaml
wget https://raw.githubusercontent.com/kubernetes/heapster/master/deploy/kube-config/influxdb/heapster.yaml
wget https://raw.githubusercontent.com/kubernetes/heapster/master/deploy/kube-config/influxdb/influxdb.yaml
kubectl create -f ./最后确认所有的pod都处于running状态,打开Dashboard,集群的使用统计会以仪表盘的形式显示出来。
7. 部署示例应用
接下来部署一个基于微服务的应用,做一个测试:
kubectl create namespace sock-shop
kubectl apply -n sock-shop -f "https://github.com/microservices-demo/microservices-demo/blob/master/deploy/kubernetes/complete-demo.yaml?raw=true"这个应用服务的镜像较多,需要耐心等待:
kubectl get pod -n sock-shop -o wide
NAME READY STATUS RESTARTS AGE IP NODE
carts-153328538-8r4pv 1/1 Running 0 12m 10.244.0.10 node1
carts-db-4256839670-cw9pr 1/1 Running 0 12m 10.244.0.9 node1
catalogue-114596073-z2079 1/1 Running 0 12m 10.244.2.5 node3
catalogue-db-1956862931-ld598 1/1 Running 0 12m 10.244.1.6 node2
front-end-3570328172-vfj7r 1/1 Running 0 12m 10.244.0.11 node1
orders-2365168879-h3zwr 1/1 Running 0 12m 10.244.1.7 node2
orders-db-836712666-954nd 1/1 Running 0 12m 10.244.2.6 node3
payment-1968871107-9511t 1/1 Running 0 12m 10.244.0.12 node1
queue-master-2798459664-h99nt 1/1 Running 0 12m 10.244.1.8 node2
rabbitmq-3429198581-2hvzl 1/1 Running 0 12m 10.244.2.7 node3
shipping-2899287913-kxt4k 1/1 Running 0 12m 10.244.0.13 node1
user-468431046-6tf0w 1/1 Running 0 11m 10.244.1.9 node2
user-db-1166754267-qrqnf 1/1 Running 0 11m 10.244.2.8 node3kubectl -n sock-shop get svc front-end
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
front-end 10.103.64.184 <nodes> 80:30001/TCP 13m大功告成O(∩_∩)O~,在浏览器中打开http://<NodeIP>:30001,浏览一下这个应用吧。