RADOS简介
从Ceph官方文档摘录的架构图如下。RADOS是Ceph中最关键的部分,RADOS是一个支持海量对象的分布式对象存储。
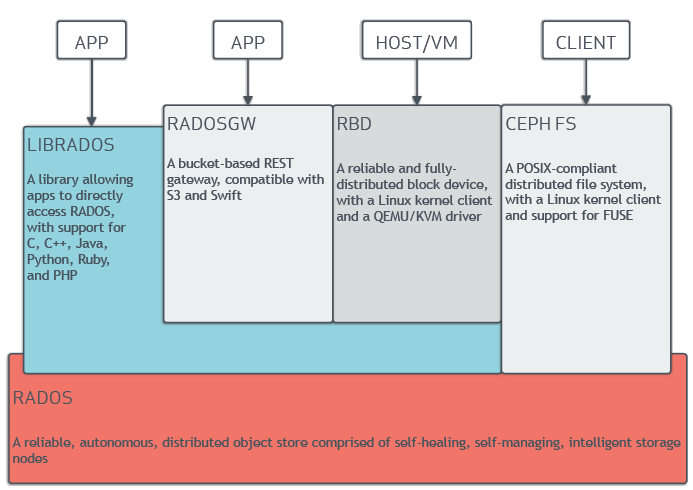
RADOS主要由两部分组成:
- Monitor节点集群:由少量的Monitor组成的小规模集群,负责管理的Map。Cluster Map是整个RADOS系统的关键数据结构,包含集群中全部成员、关系、属性等信息以及管理数据的分发。
- OSD节点集群:由大规模的OSD(Object Storage Device)组成的集群,负责存储所有的对象数据。
在物理结构上RADOS是由大量的存储节点组成,每个节点拥有自己的CPU、内存、硬盘、网络等硬件资源,并运行着操作系统和文件系统,OSD集群就是这些存储节点。、 而节点管理和数据分发策略都由Monitor负责,并为Client提供存储接口。
Ceph Monitor Map
本篇我们一起来学习一下Ceph Monitor。前面提到了Monitor负责管理Cluster Map,那么在Ceph集群中包含哪些Cluster Map呢? 借助我们之前部署的Ceph集群来看一下这些Cluster Map。
ceph -s
cluster 4873f3c0-2a5b-4868-b30e-f0c6f93b800a
health HEALTH_OK
monmap e1: 1 mons at {c1=192.168.61.31:6789/0}
election epoch 6, quorum 0 c1
osdmap e61: 2 osds: 2 up, 2 in
flags sortbitwise,require_jewel_osds
pgmap v2719: 192 pgs, 2 pools, 76900 kB data, 35 objects
12754 MB used, 182 GB / 195 GB avail
192 active+cleanMonitor Map
Monitor Map包含所有Monitor节点的信息,包括集群ID,主机名,IP和端口等。
ceph mon dump
dumped monmap epoch 1
epoch 1
fsid 4873f3c0-2a5b-4868-b30e-f0c6f93b800a
last_changed 2017-01-17 20:24:52.361450
created 2017-01-02 17:24:52.361450
0: 192.168.61.31:6789/0 mon.c1可以看出当前集群中只有一个MON节点。
OSD Map
OSD Map包含Ceph Pool的pool ID,名称,类型,副本以及PGP信息;另外包含OSD的数量、状态、最细清理间隔、OSD所在主机信息。
ceph osd dump
epoch 61
fsid 4873f3c0-2a5b-4868-b30e-f0c6f93b800a
created 2017-01-17 20:24:52.728134
modified 2017-01-19 14:48:48.730141
flags sortbitwise,require_jewel_osds
pool 0 'rbd' replicated size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_c hange 1 flags hashpspool stripe_width 0
pool 2 'kube' replicated size 2 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 128 pgp_num 128 las t_change 31 flags hashpspool stripe_width 0
removed_snaps [1~3]
max_osd 2
osd.0 up in weight 1 up_from 45 up_thru 48 down_at 44 last_clean_interval [34,43) 192.168.61.32:6800/33 66 192.168.61.32:6801/3366 192.168.61.32:6802/3366 192.168.61.32:6803/3366 exists,up 1fd0e8ad-aaca-4c6a-a9 97-28adf3833508
osd.1 up in weight 1 up_from 47 up_thru 48 down_at 42 last_clean_interval [36,41) 192.168.61.33:6800/33 45 192.168.61.33:6801/3345 192.168.61.33:6802/3345 192.168.61.33:6803/3345 exists,up 0df0a29a-c14e-4f1f-9d 8f-9d121a72975fPG Map
PG Map包含当前的PG版本、时间戳、空间使用比例以及每个PG的基本信息。
ceph pg dump
dumped all in format plain
version 2720
stamp 2017-02-03 19:36:06.646630
last_osdmap_epoch 61
last_pg_scan 61
full_ratio 0.95
nearfull_ratio 0.85
......CRUSH Map
包含集群存储设备信息,故障层次结构以及存储数据时失败域规则信息。
ceph osd crush dumpCeph Monitor
Ceph Monitor运行为一个轻量级的进程,一般情况下只会消耗很少的系统资源。大多数场景下可以选择入门级的CPU、千兆网卡即可,但是需要有足够大的磁盘空间来保存集群日志。 Ceph Monitor集群通过Paxos分布式协调算法来进行leader的选举。因为是通过法定人数选举的,所以当Ceph集群中有多个Monitor时,Monitor的数量应该是一个奇数,一般线上环境应该至少有3个。
前面在试验环境中初始化的Ceph集群只有一个MON。
192.168.61.30 c0 - admin-node, deploy-node
192.168.61.31 c1 - mon1
192.168.61.32 c2 - osd.1
192.168.61.33 c3 - osd.2接下来我们添加两个MON,即把c2,c3也作为MON节点。
修改ceph.conf,在global章节加入:
mon_initial_members = c1,c2,c3
mon_host = 192.168.61.31,192.168.61.32,192.168.61.33
public network = 192.168.61.0/24在admin-node上将配置文件推送到各个节点:
ceph-deploy --overwrite-conf config push c1 c2 c3添加MON节点:
ceph-deploy mon create c2 c3ceph -s
cluster 4873f3c0-2a5b-4868-b30e-f0c6f93b800a
health HEALTH_OK
monmap e11: 3 mons at {c1=192.168.61.31:6789/0,c2=192.168.61.32:6789/0,c3=192.168.61.33:6789/0}
election epoch 26, quorum 0,1,2 c1,c2,c3
osdmap e66: 2 osds: 2 up, 2 in
flags sortbitwise,require_jewel_osds
pgmap v2924: 192 pgs, 2 pools, 76900 kB data, 35 objects
12844 MB used, 182 GB / 195 GB avail
192 active+clean移除MON节点:
ceph-deploy mon destroy c2 c3