现在一些开源的分布式调用跟踪系统大多都参考了Google的论文《Dapper,大规模分布式系统的跟踪系统》。 这里我们简单学习一下Dapper的基本概念。
分布式调用跟踪系统实际上是随着微服务才火起来的一个概念,当然Google在很多年前已经微服务化了,所以他的分布式跟踪理论应该是最成熟的。 分布式跟踪系统出现的原因简单的说是因为在分布式系统中一次请求中会包含很多的RPC,迫切需要一些可以帮助理解系统行为和分析性能问题的工具,需要断定具体哪个服务拖了后腿。
实现分布式跟踪系统的需求
Dapper论文中对实现一个分布式跟踪系统提出了如下几个需求:
- 性能低损耗:分布式跟踪系统对服务的性能损耗应尽可能做到可以忽略不计,尤其是对性能敏感的应用不能产生损耗
- 对应用透明:即要求尽可能用非侵入的方式来实现跟踪,尽可能做到业务代码的低侵入,对业务开发人员应该做到透明化
- 可伸缩性:高伸缩性是指不能随着微服务和集群规模的扩大而使分布式跟踪系统瘫痪
- 跟踪数据可视化和迅速反馈:即要有可视化的监控界面,从跟踪数据收集、处理到结果的展现尽量做到快速,就可以对系统的异常状况作出快速的反应
- 持续的监控:即要求分布式跟踪系统必须是7x24小时工作的,否则将难以定位到系统偶尔抖动的行为
Dapper论文中的例子
我们先来看Dapper论文里的一个例子:
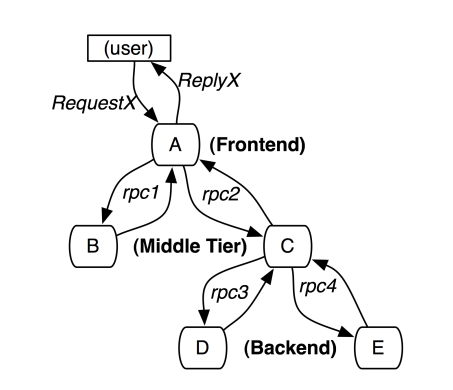
A~E分别表示五个服务,用户发起一次请求到A,然后A分别发送RPC请求到B和C,B处理请求后返回,C还要发起两个RPC请求到D和E。
Trace和Span
分布式跟踪系统要做的就是记录每次发送和接受动作的标识符和时间戳,将一次请求涉及到的所有服务串联起来,只有这样才能搞清楚一次请求的完整调用链。
在这篇论文中使用Trace表示对一次请求完整调用链的跟踪,将两个服务例如上面的服务A和服务B的请求/响应过程叫做一次Span。
我们可以看出每一次跟踪Trace都是一个树型结构,Span可以提现出服务之间的具体依赖关系。
每个跟踪树Trace都要定义一个全局唯一的TraceID,论文中推荐用64位的整数表示,在这个跟踪中的所有Span都将获取到这个TraceID。 每个Span都有一个ParentSpanID和它自己的SpanID。上图那个例子中A服务的ParentSpanID为空,SpanID为1;然后B服务的ParentSpanID为1,SpanID为2;C服务的ParentSpanID也为1,SpanID为3,以此类推。
Span的内部结构
下面看一下Span的内部结构,Span除了记录ParentSpanID和自己的SpanID外,还会记录自己请求其他服务的时间和响应时间。这里记录时间有个问题就是每个服务器的时间可能不是完全相同,为了解决这个问题需要约定一个前提,即RPC客户端必须发出请求后,服务端才能收到,即如果服务端的时间戳比客户端发出请求的时间戳还靠前,那么就按请求时间来算,响应时间也是如此。
下图是一个Span的细节图:
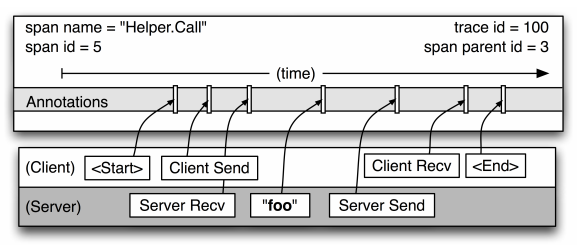
从这个图可以首先能看出来这个Span是一次"Hello.Call"调用,SpanID是5,ParentSpanID是3,TraceID是100。
我们重点看一下Client Send, Server Recv, Server Send, Client Recv即CS, SR, SS, CR。
CS:客户端发送时间SR:服务端接收时间SS: 服务端发送时间CR: 客户端接收时间
通过收集这四个时间戳,就可以在一次请求完成后计算出整个Trace的执行耗时和网络耗时,以及Trace中每个Span过程的执行耗时和网络耗时。
- 服务调用耗时 = CR - CS
- 服务处理耗时 = SS - SR
- 网络耗时 = 服务调用耗时 - 服务处理耗时
生成Span
我们已经初步了解了Span的组成,那么怎么生成Span呢? 论文中提到了两种方式: 黑盒(black-box)和基于标注(annotation-based)的监控方案。黑盒的方式目前没有开源实现这种方式,论文说Google自己也没用,说是用到了统计回归的方式,论文里也没有详细介绍。另外一种方式就是标注,但是这样就会侵入代码,所以应尽可能少的侵入,尽可能少的改动代码。
我们来看一下基于标注Annotation的方式,具体的做法就是根据请求中的TraceID来获取Trace这个实例,各种编程语言有各自的方式。获取到Trace实例后就可以调用Recorder来记录Span了,记录值先直接以日志的形式存在本地,然后跟踪系统会启动一个Collector Daemon来收集日志,然后整理日志写入数据库。 解析的日志结果建议放在BigTable(Cassandra或者HDFS)这类稀疏表的数据库里。因为每个Trace携带的Span可能不一样,最终的记录是每一行代表一个Trace,这一行的每一列代表一个Span。
对于减少代码的侵入性,论文建议将核心跟踪代码做的很轻巧,然后把它植入公共组件中,比如线程调用、控制流以及RPC库。
采样率
分布式跟踪系统的实现要求是性能低损耗的,尤其在生产环境中分布式跟踪系统不能影响到核心业务的性能。 Google也不可能每次请求都跟踪的,所以要进行采样,每个应用和服务可以自己设置采样率。采样率应该是每个应用自己的配置里配置的,这样每个应用可以动态调整,特别是刚应用刚上线使可以适当调高采样率。
一般在系统峰值流量很大的情况下,只需要采样其中很小一部分请求,例如1/1000的采样率,即分布式跟踪系统只会在1000次请求中采样其中的某一次。